
The Vertical and the Loop: valuation, compute, and the Anthropic IPO
Anthropic’s confidential trillion-dollar IPO, the three-silicon bet underneath it, the physics of a token, and the circular machine that pays for the frontier.



Reported and estimated figures. Anthropic's S-1 is confidential; none of the below is yet an audited, publicly filed fact.
A note on the byline. This analysis is written by The Software Frontier. We have no access to Anthropic’s non-public financials, no instruction to flatter the company, and no stake in the outcome. Everything here is drawn from public reporting, third-party regulatory filings, analyst estimates, and published silicon benchmarks, attributed inline. Where the company looks strong we say so. Where the bears have the better argument, we say that too. Treat the byline as a reason for scrutiny, not for trust.
Three rockets, one launch window
For the first time in the history of American capital markets, three private companies are attempting to go public in a single year at valuations above one trillion dollars each. That has never happened once. It is now scheduled to happen three times in roughly one hundred days.
SpaceX, which by 2026 had combined with xAI into a single entity, filed its public S-1 on May 20 and is expected to begin trading on June 12, seeking upwards of seventy-five billion dollars, according to Datacenter Dynamics’ reading of the prospectus.
OpenAI filed a confidential draft registration on May 22, targeting a fourth-quarter listing that could come as early as September, with Goldman Sachs, Morgan Stanley, and JPMorgan leading, per the Wall Street Journal and CNBC. And on Monday, June 1, Anthropic started its own clock, confidentially filing an IPO prospectus with the SEC and confirming it in a public statement.
Reuters reported back in December that the company had already engaged Wilson Sonsini, the firm that managed Google’s 2004 IPO, to prepare.
PitchBook’s Harrison Rolfes told CNN that two trillion-dollar filings in such a short window represent the largest concentration of pre-IPO capital ever brought to market at once. He was counting two. There are three.
Wedbush’s Dan Ives, who has tracked this complex for years, called the moment an opening of the floodgates for an IPO market that has been largely shut.
This piece is about the middle rocket. Anthropic is the most interesting of the three not because it is the largest, but because it sits at the exact center of every structural question the AI buildout has raised: the quality of AI revenue, the physics and economics of inference, the rivalry between three incompatible silicon stacks, and the circular capital flows that critics compare to the vendor-financing collapse of the dot-com era. To price Anthropic is to price the entire complex.
There is a complication, and it is the most important sentence in this report. The filing is confidential. Under SEC rules for emerging growth companies, the prospectus stays private until roughly fifteen days before a public roadshow.
Which means that as of this writing, the most anticipated technology IPO in a generation is being valued by the market on numbers that no auditor has signed for public release.
Everything you are about to read about Anthropic’s financials is reported, estimated, or projected. None of it is yet a filed, audited fact. Hold that thought. We will return repeatedly to why it matters more here than almost anywhere else.
The vertical
Start with the revenue curve, because it is the reason any of this is happening, and because it does not look like a curve. It looks like a wall.
Anthropic reported roughly one billion dollars in annualized revenue at the end of 2024. By the end of 2025 that figure was around nine billion. After closing its Series G in February 2026 it was near fourteen billion. By early April, multiple outlets put the run-rate above thirty billion.
In May, per CNBC’s account of the filing, Anthropic disclosed a run-rate of forty-seven billion dollars, a figure echoed at roughly forty-five billion by the research firm Sacra.
Read that sequence again: one, nine, fourteen, thirty, forty-seven. The jump from fourteen to forty-seven happened in about four months. There is no precedent for this in enterprise software.
The closest analogue is not a software company at all. It is a commodity in a shortage, which is exactly what frontier inference capacity has become.

The composition matters more than the level. Roughly eighty percent of revenue comes from enterprises, per TipRanks, almost the inverse of OpenAI’s consumer-heavy base. Futurum’s Nick Patience notes that eight of the Fortune 10 are now paying customers. More than three hundred thousand businesses run Claude.
The count of customers spending a million dollars or more per year crossed one thousand by April, double the roughly five hundred in February. And one product, Claude Code, reached about one billion dollars in annualized revenue within six months of launch, a developer-tool adoption speed that AI Weekly, citing WSJ figures, called a new category benchmark.
That last fact is double-edged, and we will sharpen the second edge later. For now, note the shape: this is not a consumer novelty that might churn. It is a deeply embedded enterprise dependency growing into core workflows.
That is the most durable kind of revenue there is. It is also the kind that invites a backlash when the bill arrives, which is precisely what is now starting to happen.
The margin question, which is really two companies
The number everyone quotes is revenue. The number that decides whether Anthropic is worth a trillion dollars is gross margin, and on gross margin Anthropic is two entirely different businesses wearing the same name.
In 2024, Anthropic’s gross margin was negative ninety-four percent, per data compiled by TradingKey. It cost nearly two dollars of compute to deliver one dollar of revenue. By 2025 that had swung to somewhere around forty to fifty percent.
The company’s own projection, reported by Sacra and Seeking Alpha, is for gross margin to reach roughly seventy-seven percent by 2028.

A Substack analysis by Shanaka Anslem Perera framed the stakes more precisely than any sell-side note I have read: revenue at forty percent gross margin and revenue at seventy-seven percent gross margin are not the same business with different costs.
They are different businesses. The whole valuation rests on the assumption that the second business is the one arriving. The bear case rests on the possibility that it is not.
Why might margins expand so dramatically? The answer is not hand-waving. It is mechanical, it is grounded in the physics of how a token is produced, and it is the strongest single pillar of the bull case. Section VII takes it apart piece by piece.
But first we have to understand what Anthropic actually runs Claude on, because the margin story and the silicon story are the same story.
The profitability that may not be one
In mid-May, the Wall Street Journal reported that Anthropic is on pace to post its first operating profit in the second quarter of 2026: roughly $10.9 billion in revenue against an expected operating profit of about $559 million, more than doubling the $4.8 billion booked in Q1.
AI Weekly’s summary of the WSJ figures framed this as the moment Anthropic crosses into covering its own costs, a milestone that, if real, changes the fundraising calculus for the entire frontier sector. Investors could finally model a path to returns rather than an indefinite subsidy.
The technology critic Ed Zitron argues the milestone is partly an artifact of timing, and the argument deserves engagement rather than dismissal. The mechanism: under the compute deal Anthropic struck with the xAI unit of SpaceX, Anthropic pays $1.25 billion per month for the Colossus 1 cluster, a figure that emerged from SpaceX’s own S-1 and was reported by TechCrunch.
That is roughly fifteen billion dollars a year. But the deal carries a discounted rate for the first two months while xAI completes its ramp, and those two discounted months fall, conveniently, in exactly the quarter Anthropic is using to claim its first operating profit.
Zitron’s point is not that Anthropic is lying. It is that a 559-million-dollar operating profit is a thin margin on a temporarily depressed cost base, and that when the SpaceX rate steps up to its full level, the same quarter’s economics look different.
Whether you find this damning or merely worth watching depends on your priors. What is not in dispute is that the profitability claim and the compute deal are entangled, and that a confidential S-1 means we cannot yet see how the company books the ramp discount.
This is the first concrete reason the confidentiality matters: the single most important narrative claim, that Anthropic is now profitable, sits on a cost structure we cannot inspect.
The three-silicon bet
Now the part that, in the end, actually decides the future: where the compute comes from, what it runs on, and who controls it.
Anthropic has done something no other frontier lab has managed. It trains and serves Claude across three mutually incompatible silicon stacks at once: Amazon’s Trainium, Google’s TPU, and Nvidia’s GPUs (the latter rented, remarkably, from a rival).
This is not an accident of procurement. It is a deliberate hedge against the single greatest risk a frontier lab faces, which is being captive to one supplier’s roadmap, pricing, and power budget.
Anthropic CFO Krishna Rao framed the multi-vendor approach to CNBC as spreading workloads across vendors to tune for price, performance, and power. Read it as insurance.
Amazon and Trainium
On April 20 and 21, Amazon and Anthropic announced an expanded partnership that, per Global Data Center Hub’s reconstruction, totals up to thirty-three billion dollars in committed Amazon equity: five billion in fresh equity at a $350 billion pre-money valuation, up to twenty billion more tied to milestones, on top of eight billion deployed from 2023 to 2025.
In exchange, Anthropic committed to spend more than one hundred billion dollars on AWS over the next decade and to deploy up to five gigawatts of Trainium capacity. The engine is Project Rainier, which Anthropic’s own announcement describes as already running over one million Trainium2 chips.
The Indiana campus alone, per Global Data Center Hub, spans twelve hundred acres across seven buildings and scales toward 2.2 gigawatts at full build-out.
The commitment spans Trainium2, Trainium3, and the still-unannounced Trainium4, with Amazon’s Annapurna Labs taking design feedback from the lab that stresses the chips hardest.
Google and TPUs
The Google relationship is older and, in valuation terms, arguably the better bargain. CNBC reported that before the latest deal Google’s stake exceeded three billion dollars at roughly fourteen percent, built from a three-hundred-million-dollar 2023 check for about ten percent plus a two-billion-dollar follow-on.
In October 2025 the two announced a cloud deal for up to one million TPUs worth tens of billions. Then on April 24, 2026, Google committed up to forty billion dollars more in cash and compute, per TechCrunch and CNBC, expanding to five gigawatts of TPU capacity over five years. A Broadcom securities filing put the associated next-generation TPU figure at 3.5 gigawatts.
The Motley Fool’s Billy Duberstein argued Google is getting a screaming bargain, partly because a guaranteed five-gigawatt anchor tenant de-risks Alphabet’s own enormous capex. He is probably right, and the reason he is right is the same reason the structure is fragile, which is the subject of future discussions.
Nvidia, via xAI’s Colossus
This is the strangest leg, and the most revealing. On May 6, at its own Code with Claude developer conference, Anthropic announced it would take essentially all the compute at Colossus 1, the Memphis supercomputer built by xAI and now owned by the merged SpaceX entity.
Per xAI’s release, Colossus 1 houses over 220,000 Nvidia GPUs spanning H100, H200, and GB200 accelerators, roughly 300 megawatts. The timing was not accidental: with usage of xAI’s own Grok having dropped, Colossus 1 sat underused, which is what freed its full capacity for Anthropic, per TechCrunch’s reading of the S-1.
Anthropic’s chief compute officer Tom Brown said on the record that the company would expand onto Nvidia GB200 capacity in the larger Colossus 2 through June, per Axios. TechCrunch later reported, from SpaceX’s S-1, that Anthropic will pay $1.25 billion per month through May 2029, a deal that could bring the Musk entity over forty billion dollars in revenue, with either side able to terminate on ninety days’ notice.
The arrangement is pointed at consumer capacity, directly improving Claude Pro and Claude Max. The irony is thick enough to cut: Anthropic, the lab founded by OpenAI defectors, is now renting its consumer compute from Elon Musk, who wrote on X in February that the company hates Western civilization, per CNBC. Business is business.

Chips, racks, and the CUDA moat
If you read only one section as an engineer, read this one and the next. The headline question is simple to state and hard to answer:
can custom silicon actually serve a frontier model, or is Nvidia’s lead structural?
Anthropic is the live experiment, and the early data is more interesting than either camp admits.
Start at the chip. AWS shipped Trainium3 in December 2025 on TSMC’s 3nm N3P node, the most advanced process in any shipping AI accelerator, per Tom’s Hardware and the spec compilations at IntuitionLabs and Awesome Agents, reaching broad availability in early 2026.
Each Trainium3 chip delivers about 2.52 petaflops of MXFP8 compute with 144 GB of HBM3e and 4.9 TB/s of memory bandwidth, with eight NeuronCore-v4 engines and a NeuronLink-v4 interconnect at 2 TB/s. AWS claims roughly 2x the per-chip compute of Trainium2, rising to about 4.4x at the 144-chip UltraServer level, with 4x better energy efficiency.
Google’s TPU v7, codenamed Ironwood and announced in 2025, delivers about 4.6 petaflops of FP8 per chip with 192 GB of HBM and 7.37 TB/s of bandwidth, which analysts at Introl described as on par with Blackwell.
Nvidia’s B200, by contrast, delivers roughly 9 petaflops of FP8 per chip with sparsity (about 4.5 dense), per Nvidia’s datasheet. Its headline figure near 18 to 20 petaflops is an FP4 number, a lower-precision format, so comparing like for like at FP8 is the only fair reading.

Now move up one level, to the rack, where AI is actually deployed. AWS packs 144 Trainium3 chips into a liquid-cooled Trn3 Gen2 UltraServer that delivers roughly 362 petaflops of FP8, 20.7 TB of HBM3e, and an aggregate 705.6 TB/s of memory bandwidth.
Per Tom’s Hardware and Oplexa’s analysis, that puts the UltraServer essentially level with Nvidia’s flagship GB300 NVL72 at rack scale, at an estimated fifty percent lower cost per workload and roughly forty percent better energy efficiency.

This is the crux that most coverage misses. The custom-silicon competition is not happening at the transistor. It is happening at the system and at the dollar.
Amazon and Google close a brutal single-chip deficit through dense integration, liquid cooling, and proprietary scale-up fabrics: Nvidia calls its fabric NVLink, Google calls its ICI, AWS calls its NeuronLink. Once you are buying racks rather than chips, and once you weight by cost and power rather than raw flops, the gap collapses.
Memory is the other half of the story, and it is the half that governs inference. As we will show in detail, modern serving is memory-bandwidth-bound, not compute-bound, which is why the per-token cost curve is so sensitive to HBM.
Here the three are closer than the compute numbers suggest, and Nvidia’s lead is narrower.

Inside the die: systolic arrays versus SIMT
The reason a custom accelerator can rival a GPU it trails on paper comes down to dataflow.
Each Trainium3 chip carries eight NeuronCore-v4 engines, and each engine is built around systolic arrays: a 128 by 128 grid for BF16 and a wider 512 by 128 grid for MXFP8, backed by 32 MiB of on-core SRAM. A systolic array is the opposite of a general-purpose processor.
Weights are loaded into the grid and held stationary while activations pulse through it, so a value read once from SRAM is reused across an entire row or column of multiply-accumulate units before it retires.
On the dense matrix multiplies that dominate a transformer, that weight-stationary dataflow keeps the multiply-accumulate units near full occupancy while spending almost nothing on instruction fetch, register-file traffic, or cache coherence. Google’s TPU is the same idea at a different size: one very large matrix-multiply unit fed by a compiler that schedules the entire computation ahead of time.
Nvidia’s Blackwell takes the other path. Its streaming multiprocessors are SIMT machines: thousands of threads grouped into warps, with tensor cores doing the matrix math and a deep hierarchy of schedulers, register files, and caches feeding them.
That flexibility is the point. A GPU runs irregular control flow, dynamic shapes, sparsity, and an enormous library surface, on hardware that was never specialized to one operator. The cost of that generality is silicon and power spent on everything that is not the multiply. For the long tail of workloads, the flexibility earns its keep. For a transformer decode loop, much of it sits idle.
This is the precise reason the rack-level parity in the charts above is real rather than a marketing artifact. A frontier lab runs essentially one workload shape, the transformer, and writes its own kernels, so it does not need most of what a GPU spends transistors on, and it can drive a systolic array to a utilization a general user could never reach.
The cost it pays is the programming model. Fifteen years of CUDA, of PTX and SASS-level tuning, of cuDNN and CUTLASS and a developer base in the millions, has no equivalent on the other side. AWS answers with the Neuron SDK and its NKI kernel interface plus JAX and PyTorch support; Google answers with XLA, JAX, and Pallas.
A team with kernel engineers can reach high utilization on any of the three. An enterprise that only wants a model behind an API cannot, which is why the moat protects Nvidia at the bottom of the market and erodes at the very top, where Anthropic operates.
The last equalizer is the fabric. A single chip never serves a frontier model alone, so what matters is how fast many chips behave as one. Nvidia’s NVLink 5 moves about 1.8 terabytes per second per GPU through an NVSwitch fabric; AWS NeuronLink-v4 moves about 2 terabytes per second per chip; Google’s ICI wires its pods into a three-dimensional torus.
Tensor parallelism forces every chip to exchange a slice of activations on every layer, and expert parallelism in a mixture-of-experts model adds an all-to-all shuffle of tokens to their chosen experts, so scale-up bandwidth, not raw per-chip flops, is what lets 144 Trainium3 act like one giant accelerator with 706 terabytes per second of aggregate memory bandwidth. The per-chip FLOPS gap is what the slides show. The scale-up fabric is what the workload feels.
So why has nobody else pulled this off? Because the real moat was never the silicon. It is the software. Nvidia’s CUDA is fifteen years of libraries, kernels, compilers, and developer muscle memory.
AWS counters with the Neuron SDK and JAX and PyTorch support; Google has its own mature stack. For the long tail of enterprises, porting off CUDA is a non-starter: the engineering cost dwarfs the hardware savings.
But a frontier lab is the one customer that can pay that cost, because it writes its own kernels, owns its own stack, and has the systems talent to make a non-CUDA chip productive.
That is precisely why Anthropic is the perfect partner to validate custom silicon, and why Amazon and Google paid tens of billions in equity to make it their anchor tenant. Anthropic reportedly fed design input directly into Trainium3, per Awesome Agents.
The lab is not just renting the chips. It is co-designing the thing meant to dethrone the incumbent.
One quiet beneficiary deserves a name: Broadcom. It co-designs Google’s TPU, supplies the connectivity silicon that stitches these racks together, and, per The Motley Fool citing Broadcom’s own disclosures, booked roughly a ten-billion-dollar TPU order plus an additional eleven billion in hardware tied to Anthropic.
In a gold rush, the firm selling the most shovels to the most miners is often the cleaner trade. Hold that for the market section.
Caveat where it is due. Nvidia’s roadmap does not stand still: B200 and GB200 are reportedly sold out through mid-2026 against a backlog near 3.6 million units, per IntuitionLabs, and Vera Rubin, due in the second half of 2026 with HBM4 and a Rubin NVL144 rack at 3.6 exaflops of dense FP4, extends the lead at the top.
The near-term threat to Nvidia is not revenue. Demand still dwarfs supply. The threat is the long-run margin structure that depends on hyperscalers having no realistic alternative. Anthropic’s three-silicon bet is the clearest signal yet that the alternative is becoming real.
The cost of a token
The bull case for Anthropic’s margin is a claim about physics and software, not accounting. To judge it you have to understand how a single token is actually produced, and why the cost of producing it is collapsing roughly tenfold a year.
This is the section the financial press cannot write and your readers care about most.
Two phases, one bottleneck
Serving a language model has two phases with opposite cost structures. Prefill ingests the prompt: every input token is processed in parallel, the arithmetic is dense, and the accelerator runs near its compute ceiling. Prefill is compute-bound, and it is cheap per token because parallelism is high.
Decode generates the answer one token at a time, autoregressively, and here is the trap: to produce each new token, the hardware must stream the model’s entire active weight set out of high-bandwidth memory.
Decode is therefore memory-bandwidth-bound, not compute-bound. As the Inworld and Spheron benchmark teardowns put it, reading model weights during decode is the primary bottleneck for autoregressive generation.
This single fact is why the memory-bandwidth chart in the previous section matters more than the flops chart, and why a Trainium3 or a TPU v7, which trail Nvidia badly on raw flops but sit within striking distance on bandwidth, can serve inference competitively. The frontier is not compute-starved. It is bandwidth-starved.
Two structures sit on top of this. The KV cache stores the attention keys and values for every prior token, so it grows with context length and with batch size, and it competes for the same scarce HBM capacity and bandwidth; long-context serving is expensive precisely because, as CloudRift’s benchmarks note, it stresses KV-cache traffic.
And batching is the lever that makes serving economic at all: by processing many requests together, each expensive weight-read from HBM is amortized across many sequences, so throughput, and therefore cost per token, depends enormously on how full the batch is.
GMI Cloud’s teardown makes the point concrete: an H100 running Llama 70B in FP8 generates roughly two to three thousand tokens per second at batch 32, about $0.19 to $0.29 per million output tokens, and the same GPU at fifty percent utilization sees its effective cost per token roughly double. Utilization is not a footnote. It is half the unit economics.
Three levers that crush cost
An academic study circulating on arXiv this year, modeling what it calls a tiered Super-Moore effect, decomposes inference cost into hardware, labor, and a technology index that captures architectural innovation. Its key finding is that the technology index has improved far faster than the hardware alone. Three levers do most of the work.
Quantization. Moving the numerical format of the weights from FP16 to FP8 to FP4 or INT4 halves the bytes per parameter at each step. Because decode is bandwidth-bound, fewer bytes per weight means more tokens per second on the same silicon, almost linearly.
Spheron measures FP8 cutting effective cost per token by roughly half on H100 and H200 by doubling throughput with no extra GPUs; Blackwell’s FP4 tensor cores push it further still. Quantization is close to a free lunch until model quality degrades, and the frontier labs have become expert at quantizing right up to that line.
Mixture of experts. A dense model activates all its parameters for every token. A mixture-of-experts model routes each token through only a small subset.
The arXiv study quantifies the canonical example: DeepSeek’s architecture carries 671 billion total parameters but activates only 37 billion per token, an eighteen-fold reduction in per-token compute with no proportionate quality loss, and it operates independently of any hardware trend.
MoE is the single largest architectural reason a frontier-class answer is no longer a frontier-class expense.
Algorithmic serving. FlashAttention removed the memory bottleneck inside the attention kernel; speculative decoding, which drafts several tokens with a small model and verifies them with the large one, cuts latency two to three times, per Introl; continuous batching and paged KV caches keep utilization high. None of these require new chips. They are software, and software ships continuously.
The hardware levers compound on top: Blackwell’s B200 carries 2.4 times the memory bandwidth of an H100 and enough capacity (192 GB) to hold models up to roughly 96 billion parameters in FP16, or 192 billion in FP8, on a single GPU, which removes tensor-parallel communication overhead entirely, per Inworld.
Fewer cross-GPU hops means lower latency and lower cost at once.
The arithmetic of serving
Make the bottleneck quantitative, because the precise numbers are what justify the margin. During decode, producing one token requires reading every active parameter out of high-bandwidth memory exactly once, so the single-stream token rate has a hard ceiling set by bandwidth, not by compute:
tokens/sec ≈ HBM bandwidth ÷ ( bytes-per-parameter × active parameters )
The numbers are unforgiving. A dense 70-billion-parameter model in FP8 must stream 70 GB per token; an H100 at 3.35 TB/s tops out near 48 tokens per second on a single stream, a B200 at 8 TB/s near 114.
A 405-billion-parameter model falls into the single digits. This is why latency-sensitive, single-user decoding feels slow on the largest dense models no matter how many teraflops the chip advertises: those teraflops are not the binding constraint.

The escape is batching. Because every sequence in a batch reuses the same weight read, serving 256 requests together multiplies aggregate throughput by roughly 256 with no additional weight traffic, until the KV cache or the compute ceiling intervenes.
Plotted on a roofline, decode lives far down the memory-bound slope at an arithmetic intensity near one, while prefill and training sit against the compute ceiling.
The ridge point, where a workload stops being memory-bound and becomes compute-bound, falls near 560 to 590 FLOP per byte on both H100 and B200, and decode runs one to two orders of magnitude below it.

This reframes the right efficiency metric, a point your readers will appreciate more than any valuation table. For prefill and training, the number that matters is model FLOPs utilization, MFU, typically 35 to 50 percent on a well-tuned cluster.
For decode, FLOPs utilization is nearly meaningless because the tensor cores are starved of data; the metric that matters is memory-bandwidth utilization, MBU, and the engineering goal is to keep HBM busy, not the math units. Almost every serving optimization that matters, from paged attention to continuous batching, is at bottom a scheme to raise MBU.
Quantization attacks the bytes. Halving the bytes per parameter halves the bandwidth bill per token and so roughly doubles decode throughput. The frontier has marched down the precision ladder accordingly: FP16 and BF16 at two bytes, FP8 at one, FP4 and INT4 at half a byte, with the KV cache itself increasingly stored in FP8 to stretch context.
Blackwell’s tensor cores are built for FP4; Trainium3’s wider array is built for MXFP8 microscaling. The binding constraint is quality: too-aggressive quantization raises perplexity and degrades reasoning, so labs quantize weights and cache hard while protecting the few numerically sensitive layers.

The KV cache is the tax that limits batching. Attention must keep the key and value vectors of every prior token, and that cache grows linearly with both context length and batch size, competing with the weights for the same HBM.
For a 70-billion-parameter model with grouped-query attention, the cache costs roughly 0.33 MB per token, so a single million-token context consumes more than 340 GB, beyond what a B200 holds. The cache, not the weights, is usually what caps how large a batch can run, and batch size is what sets cost per token, so KV-cache management is the hinge of serving economics.
Grouped-query and multi-query attention shrink it by sharing key and value heads; paged attention stops it from fragmenting memory; FP8 storage halves it again.

Speculative decoding attacks the sequential dependency. A small draft model proposes several tokens and the large model verifies them in one forward pass, accepting the longest correct prefix.
With a per-token draft acceptance probability near 0.7 and four drafted tokens, the expected number confirmed per verification step is about ( 1 minus 0.7 to the fifth ) divided by 0.3, near 2.8, a two to three times speedup before draft overhead.
The large model still does the same total work per accepted token; what changes is that the work happens in parallel instead of one token at a time, which is exactly what a memory-bound loop needs.
Mixture of experts attacks the parameter count. A dense model pays for all its parameters on every token; a mixture-of-experts model routes each token to a small subset, so per-token compute scales with active parameters, not total. DeepSeek’s architecture carries 671 billion parameters but activates 37 billion per token, an 18-fold cut in both the FLOPs and, decisively, the bytes streamed during decode.
The catch is twofold: all 671 billion parameters must still sit in HBM, a capacity tax that demands many chips, and routing tokens to experts requires an all-to-all step that leans on the scale-up fabric from the previous section.
MoE is the single largest reason a frontier-class answer is no longer a frontier-class expense, and it is why the dense decode ceiling above understates a well-built model: at 37 billion active parameters that same H100 serves roughly 90 tokens per second single-stream rather than five.
Stack these together, quantization halving bytes, mixture-of-experts cutting active parameters by an order of magnitude, speculative decoding parallelizing the sequence, batching amortizing every weight read, and cheaper bandwidth each hardware generation on top, and the roughly tenfold annual fall in the cost of a token stops looking like magic and starts looking like arithmetic.
That is the engine underneath the margin bridge that follows.


What it costs Anthropic to make a token
We can now build the cost side from the metal up. The exercise is illustrative, the assumptions are stated plainly, and the point is the order of magnitude, not a false-precision number.
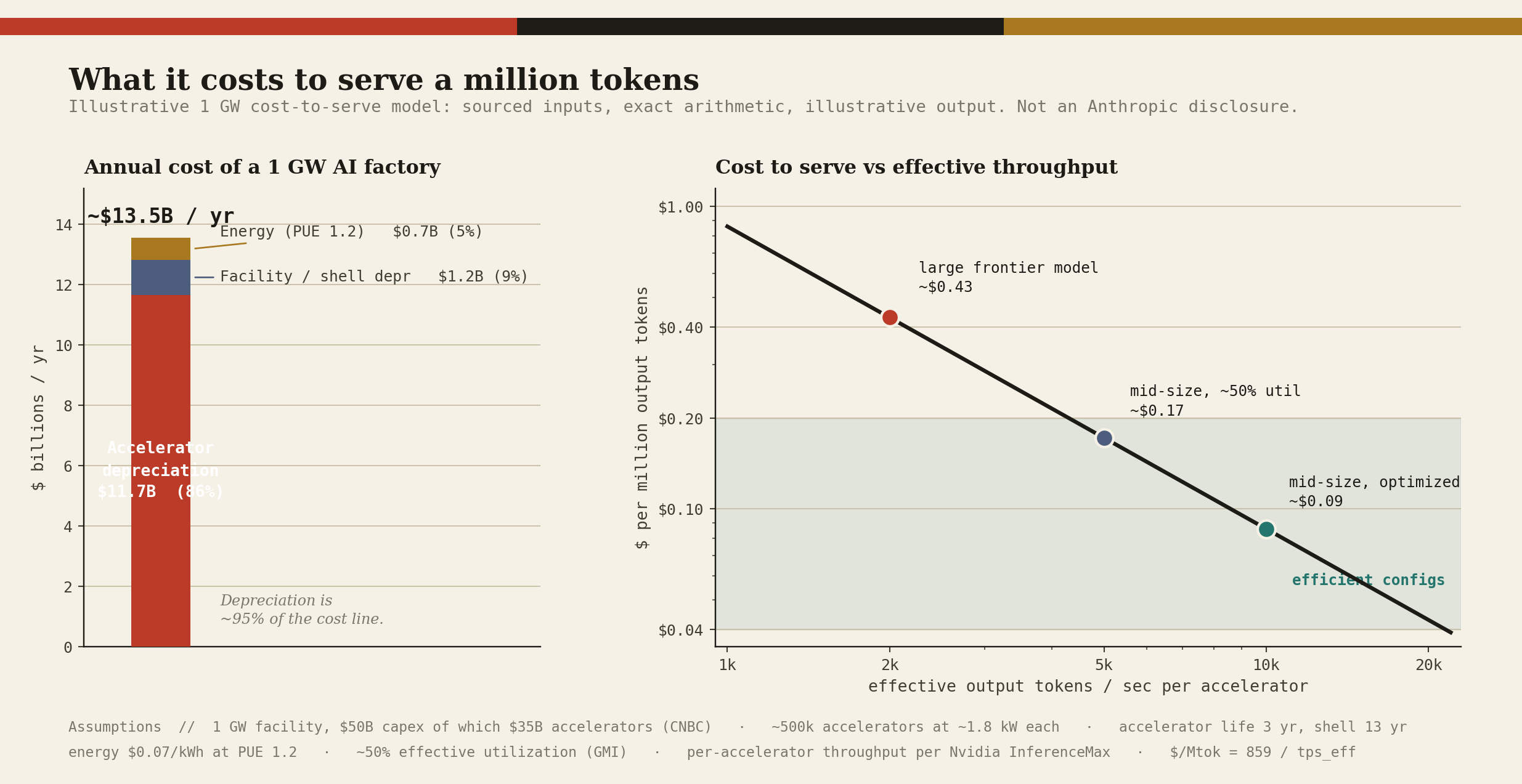
Now the other side of the ledger.
We do not know Anthropic’s blended realized price per token, because the filing is confidential, and that is the honest limit of this analysis.
What we do know: frontier output has historically listed in the five-to-fifteen-dollar range per million tokens, and Anthropic’s most capable model, the withheld Mythos preview, was priced at twenty-five dollars per million input tokens and one hundred twenty-five dollars per million output, per Sacra (a single-source figure, indicative rather than confirmed).
Even after a generous markup for the true cost of a genuine frontier model over a benchmark mid-size one, the gross spread between a cost-to-serve measured in cents and a realized price measured in dollars is wide.
That spread is the gross margin. And because the cost side falls about tenfold a year while realized prices fall more slowly, the spread widens with time. This is the physical mechanism behind the projected march from forty-five to seventy-seven percent.
Nvidia, naturally, has quantified the same loop from the supplier’s side. In its InferenceMax v1 results, the company claims a single GB200 NVL72 turns a five-million-dollar investment into roughly seventy-five million dollars of DeepSeek-R1 token revenue, a fifteen-fold return, what it calls AI-factory economics.
Treat the figure as a vendor benchmark on an idealized model, but the direction is the entire bull thesis in one number: at current token prices, a frontier accelerator generates a multiple of its cost in sellable output.

The technical bottom line
The cost half of Anthropic’s margin equation is governed by mechanisms we can see and that compound predictably: quantization, mixture-of-experts routing, algorithmic serving gains, and cheaper bandwidth per token, together delivering roughly an order of magnitude of cost reduction per year. That is why a 77% gross margin is physically plausible rather than fantastical.
The risk lives on the price half, which we cannot see. If open-weight competition (DeepSeek, Llama) and rival labs compress realized prices as fast as cost falls, the spread does not widen and the margin thesis stalls.
The bull is betting cost falls faster than price.
The bear is betting price falls to meet cost. The confidential S-1 hides exactly the number, realized revenue per token, that would settle it.
The infinite loop
Look again at the last two columns of the capital-and-compute table. Amazon is investing up to thirty-three billion into Anthropic; Anthropic is committing to spend over one hundred billion with Amazon.
Google is investing up to forty billion; Anthropic is spending tens of billions with Google. The capital flows out as equity and comes back as revenue.
CNBC said it plainly in its coverage of the Google deal: much of the investment will return in the form of revenue. This is the circular-financing question, and it is the single most important structural issue hanging over all three IPOs.
It is not unique to Anthropic. It is basically the operating system of the entire cycle.

The canonical example is on the OpenAI side. In September 2025 Nvidia announced it would invest up to one hundred billion dollars in OpenAI to fund a data center buildout equipped with, naturally, Nvidia chips.
Bernstein’s Stacy Rasgon wrote, per Business Standard, that the move would clearly fuel circular concerns. By March 2026, per BlockEden’s account, Jensen Huang was telling investors that thirty billion might be the last such investment and that the full hundred billion was not in the cards.
Nvidia also committed up to ten billion to Anthropic, which CFO Colette Kress noted could further expand the company’s bookings, a sentence that contains the whole critique in miniature: the investment expands the bookings of the company making the investment.
The scale of the web is staggering. BlockEden tallied OpenAI’s infrastructure commitments at roughly $1.15 trillion across seven vendors between 2025 and 2035.

The defenders are not stupid, and their argument deserves a fair hearing.
Dario Amodei, at the New York Times DealBook Summit in December, argued there is nothing inappropriate in principle about a party with capital and a chip interest funding a party with revenue confidence but no cash on hand.
That is a coherent description of ordinary project finance. But the historical rhyme is hard to ignore, and Bloomberg drew it explicitly: during the late-1990s internet boom, equipment makers fueled the fiber buildout with vendor financing, and when demand failed to arrive on schedule, the roundtripping that had inflated the appearance of demand amplified the collapse.
The mechanism that makes the boom look bigger is the same one that makes the bust deeper. Sequoia’s David Cahn has quantified the implied shortfall: by his framework, the AI complex needs roughly six hundred billion dollars in annual revenue to justify the capex being deployed, and the gap is widening, not closing.
“In this new world of AI, compute is revenues.”
Jensen Huang · Nvidia CEO, on the Q4 FY2026 earnings call, reframing the entire spending debate (Fortune, Benzinga)
That single line is the keystone of the bull architecture, and section VII gave it a number: at current token prices a frontier accelerator throws off a multiple of its cost in sellable output.
Huang’s claim is that capital expenditure converts into compute, compute into tokens, and tokens directly into revenue, so the spending is self-justifying.
Nvidia’s own results give the argument force: record quarterly revenue of $68.1 billion, up roughly 73 percent year over year, with $78 billion guided for the next quarter, and Kress telling investors total AI infrastructure investment could reach three to four trillion dollars annually by 2029 or 2030.
For Anthropic specifically, the loop lands on one phrase, revenue quality. When eighty percent of revenue is enterprise and a meaningful share of capital comes from the same hyperscalers whose clouds Anthropic is committing to, an investor is entitled to ask how much of the forty-seven-billion run-rate is organic demand and how much is the visible end of a closed capital loop.
Nobody outside the company knows. The filing is confidential. That is the second reason confidentiality matters more here than usual.
How do you price a wall?
Valuation is where the rigor either holds or collapses, so let us be careful, bring the public-market context the private headlines leave out, and do the one thing most coverage skips: put the multiple next to its peers.
Anthropic closed its Series G on February 12, 2026: thirty billion dollars raised at a $380 billion post-money valuation, which Perera calculated as roughly twenty-seven times annualized revenue.
By the April tender offer, the reference valuation was $350 billion, at which The Motley Fool noted the multiple had compressed to under twelve times the then-thirty-billion run-rate, simply because revenue had nearly tripled while the valuation held flat.
Then, per Let’s Data Science and CNN, Anthropic raised sixty-five billion dollars in May at a $965 billion valuation, surpassing OpenAI’s $852 billion mark for the first time.
The IPO target is above one trillion. Reuters notes the company was valued at just $183 billion as recently as last November.

The comp that reframes the question
A trillion dollars sounds insane until you place it beside what the public market already pays for AI growth.
At its IPO target, Anthropic trades near twenty-one times its forty-seven-billion run-rate, and near fourteen times its projected seventy-billion 2028 revenue. Those are not the highest multiples in the AI complex. They are far from it.

That is the reframe a careful analyst owes the reader. On a pure revenue multiple, Anthropic at a trillion dollars is cheaper than Palantir and cheaper than Databricks, while growing many times faster than either. The naive objection, the multiple is absurd, does not survive contact with the comp set.
The serious objections are about durability and quality, and there are three honest frames.
The bull frame is forward margin. If you believe the seventy-seven-percent gross margin of section VII arrives, and the company’s projection of roughly seventy billion in revenue and seventeen billion in cash flow by 2028 (Sacra), then a trillion dollars is about fourteen times 2028 revenue on the fastest-growing, highest-margin software asset ever built. Rich, but not obviously mispriced for the category leader.
The bear frame is present reality. Right now the margin is closer to forty-five percent, the company does not expect to stop burning cash until 2027 (Sacra), and the cloud bill runs to roughly eighty billion dollars through 2029. At present economics, a trillion dollars prices a future that has not arrived as though it already has, and the comp multiples assume the growth rate persists for years, which no company in history has sustained.
The skeptic frame is the one I find most useful. We are pricing the largest IPO in a generation on a confidential filing. One quiet signal cuts against the skepticism: The Motley Fool reported that when Anthropic invited long-tenured employees to sell at the $350 billion valuation, they chose to hold far more than expected. The people with the most information declined liquidity at $350 billion, and the May round then priced at nearly three times that. Insider behavior is not proof, but it is data, and here it points the same way the revenue does. Up.
How to actually get exposure
For investors who cannot buy private shares, the cleanest listed proxies are mechanical. Amazon carries up to a thirty-three-billion-dollar stake plus the AWS revenue Anthropic is committing to.
Alphabet holds roughly fourteen percent plus Google Cloud’s TPU revenue; Google Cloud grew about sixty-three percent year over year to a roughly twenty-billion-dollar quarterly run-rate, the fastest of the big three.
Broadcom is the picks-and-shovels play through TPU co-design and connectivity. Nvidia sits at the keystone with a roughly ten-billion-dollar stake and the GPU demand underneath all of it, trading near a 4.8-trillion-dollar market capitalization on the strength of Huang’s compute-is-revenues thesis.
A trillion-dollar Anthropic IPO does not just price Anthropic. As one trading desk framed it, the entire listed AI complex is likely to re-rate on Anthropic comps, not merely the company itself.
One market-structure point will matter on debut day. A listing this large arriving this fast triggers fast-entry index inclusion rules, which means passive funds become forced buyers shortly after pricing, a mechanical tailwind Yahoo Finance flagged as one reason all three trillion-dollar names may benefit from going public in quick succession. Investors will have just watched SpaceX test those rules in real time.
What the price implies: a transparent valuation
The comps above are a relative reframe, not a valuation. Here is the valuation, built the way a disciplined analyst builds one when the financials are sealed.
You cannot run a bottoms-up discounted-cash-flow model on Anthropic, because the inputs such a model needs, the actual margins, the free cash flow, the capex schedule, the share count, and the realized price per token, all sit inside the confidential S-1.
Anyone publishing a single intrinsic-value number from a DCF right now is inventing those inputs. What can be done rigorously, from fact-checked data alone, is to reframe the question around two hard primary anchors, the roughly $47 billion run-rate and the roughly $1 trillion price, and ask answerable things.
What the price requires
The most honest move is a reverse discounted-cash-flow: rather than forecast cash flows we do not have, solve for the growth the known price embeds, then judge whether it is believable.
Treat $1 trillion as today’s enterprise value, assume the market values the company at a steady-state revenue multiple m reached in year eight and discounts at a cost of capital w, and the revenue the price implies follows directly.
Revenue(yr 8) = $1,000B × (1 + w)^8 ÷ m | implied CAGR = ( Revenue(yr 8) ÷ $47B )^(1/8) - 1
With cost of capital from 9 to 13 percent and a terminal revenue multiple from 4 to 8 times, both defensible and neither touching sealed data, the implied eight-year revenue growth rate is the following.
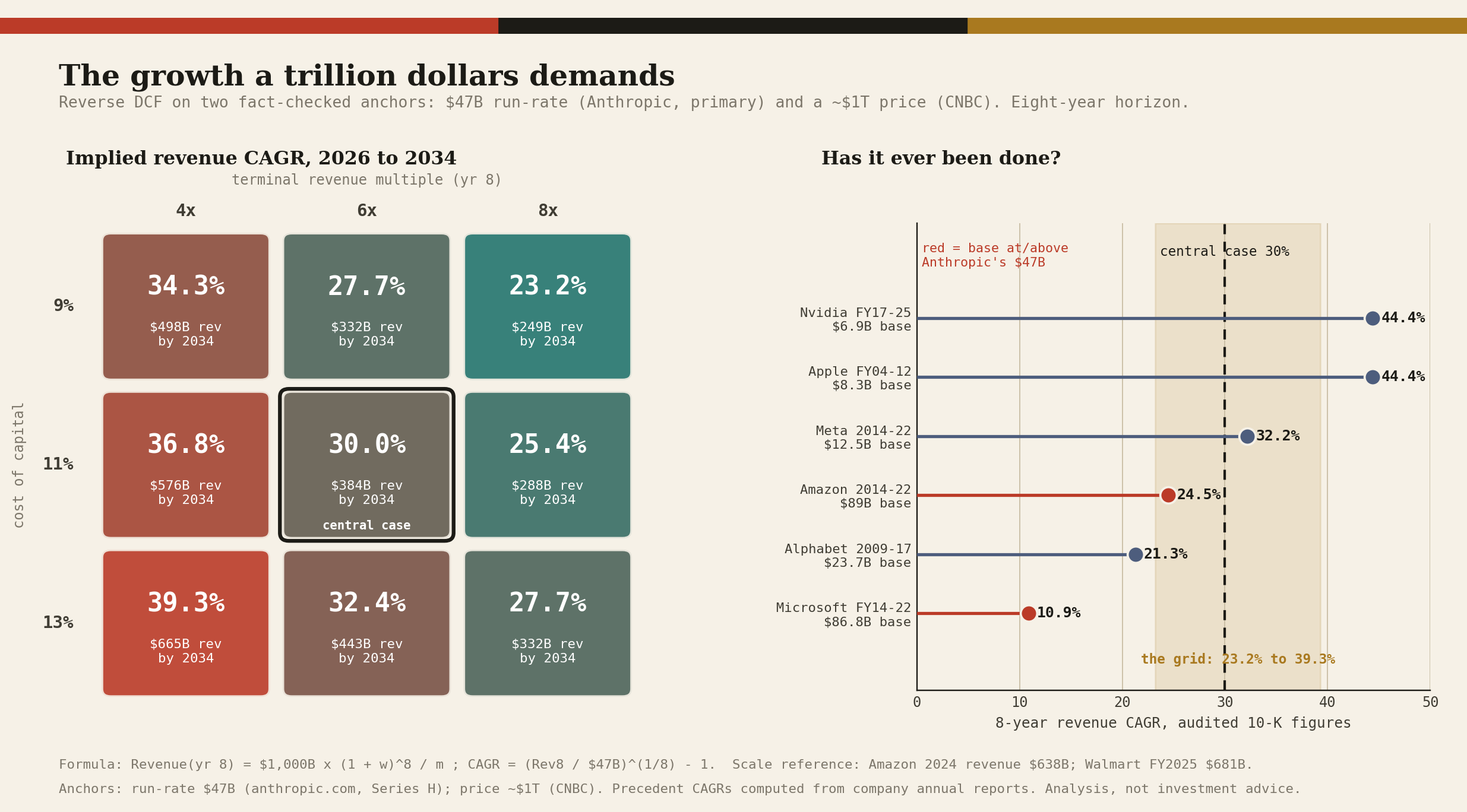
The price embeds roughly 25 to 40 percent annual revenue growth sustained for eight years, centered near 30 percent. That converts the entire debate into one question a reader can answer:
do you believe Anthropic compounds revenue at about 30 percent a year for nearly a decade?
Current growth is far above that, which gives the bull case runway; the bear case is that no company has held 30 percent for eight straight years, and open-weight price compression is the likeliest thing to break it.
The reverse DCF does not say who is right. It says, from fact-checked data, exactly what you are being asked to underwrite.
The range of outcomes
A scenario value completes the picture, anchoring the base on the company’s own 2028 projection, which is a projection and flagged as such, with a bear and a bull around it, each valued at an exit multiple and discounted to today.

One tension in the fact-checked data deserves a flag rather than a paper-over. A roughly $47 billion run-rate today against the company’s roughly $70 billion 2028 projection implies revenue growth decelerating to 15 to 20 percent a year by 2028, a sharp slowdown from the current pace.
Either the $70 billion figure predates the $47 billion run-rate and is now conservative, or management expects growth to crash, and the comps reframe that calls the price cheap rests entirely on which it is.
How to read it
The honest close is not a verdict but the underwriting question the price poses: do you believe roughly 30 percent revenue growth for eight years, and do you believe the cost half of the margin keeps falling faster than the price half.
A reader who answers yes to both can justify the trillion-dollar tag; one who doubts either cannot. The point of showing every assumption is that you can change them and watch the answer move.
This valuation is analysis, not investment advice and not a recommendation. The run-rate and price anchors are primary; the 2028 revenue and cash-flow figures are company projections; the multiples are approximate and volatile; the cost of capital, exit multiples, and scenario probabilities are explicit modeling choices made for transparency, not derived from non-public data.
A mirror, a rocket, and a clock
You cannot value Anthropic in isolation, because the IPO is partly a race, and races have positional dynamics.
OpenAI is the mirror image. Per Nerd Level Tech and Let’s Data Science, it converted to a public benefit corporation in October 2025 as OpenAI Group PBC, with the nonprofit Foundation retaining roughly twenty-six percent and board control.
Microsoft holds roughly twenty-seven percent on a diluted basis, an investment valued between about $135 billion and $228 billion depending on the mark, and ended its exclusivity arrangement in April. Sam Altman holds no equity.
OpenAI closed the largest private round in history on March 31, $122 billion at an $852 billion post-money valuation, with SoftBank, Amazon, Nvidia, and Microsoft all participating.
Revenue runs about two billion dollars a month, near a twenty-five-billion run-rate as of March, with fifty million consumer subscribers and nine million business users, per roborhythms’ compilation.
The contrast that will dominate the dueling roadshows is profitability. Multiple outlets, citing the loss figures, report OpenAI losing about $1.22 for every dollar of revenue in Q1 2026, an operating margin near negative one hundred twenty-two percent, with a projected fourteen-billion-dollar loss for the year.
Anthropic, by the disputed WSJ figures, claims a small operating profit in the same window. So the two enter the public markets at nearly identical valuations and opposite financial stories.

There is a real first-mover argument, though the precedent cuts only so far. When Lyft and Uber went public in 2019, Lyft, the first mover, popped on its debut while Uber fell on its first day; both stocks then traded poorly in the months after, so debut-day positioning is no guarantee of anything.
Both labs will seek tens of billions in fresh capital in close succession, so reaching market first plausibly matters. Anthropic’s confidential filing means it could price as early as mid-August on the SpaceX timeline, per Yahoo Finance, though Futurum reports a target as late as October; either way, likely ahead of OpenAI’s Q4 window.
Against that, the sober counterpoint: Wall Street already knows both stories intimately, and OpenAI’s S-1 will likely be public by the time Anthropic prices, letting investors judge them side by side regardless of who rings the bell first.
The rocket is the merged SpaceX entity, and it is the wild card. Its S-1 disclosed that xAI spent $12.7 billion on AI infrastructure in 2025 and another $7.7 billion in Q1 2026, per Datacenter Dynamics, and it described its one gigawatt of capacity as nameplate compute draw, explicitly noting the figure reflects installed capacity and does not represent actual utilization.
In plain terms, the GPUs are installed but may not all be powered. That single disclosure is a gift to anyone trying to separate capacity headlines from real, energized compute, and every analyst should now apply a utilization haircut to gigawatt claims across the industry, including the contracted-capacity bars in section V.
Step back and the pipeline is unlike anything the IPO market has seen. Three trillion-dollar names, plus Databricks (the only clearly profitable candidate, at a $5.4 billion run-rate growing 65 percent with positive free cash flow and a $134 billion private mark) and Cerebras (which priced around a $48.8 billion valuation on a heavily oversubscribed book).
One IPO tracker estimated combined pipeline demand at up to four times the entire 2025 US IPO market.

Stated as strongly as I can make it
A report that only sells the bull case is marketing. Here is the bear case, and it is not weak.
Demand is showing its first cracks. Axios reported, in a piece timed to the filing, that Anthropic is going public just as businesses begin to rethink their AI spend, hit with what it called sticker shock. The writer Derek Thompson has named this the great AI cost panic of 2026, the phase where Fortune 500 buyers ask whether agentic AI is worth the bill. The most cited data point is the MIT Project NANDA study from July 2025, which found that ninety-five percent of enterprise generative-AI pilots produced zero measurable profit-and-loss impact, on thirty to forty billion dollars of corporate spending.
If even a fraction of that skepticism hardens into budget discipline, the revenue surge that justifies these valuations slows exactly when the infrastructure bills come due.
The macro is stretched to dot-com proportions. The five largest Western hyperscalers are guiding toward roughly $725 billion of capex in 2026, up about seventy-seven percent from 2025’s record, per the Goldman, CreditSights, and Morgan Stanley estimates compiled by Tool Directory, with the trajectory projected past a trillion dollars annually in 2027.

The reminder that this complex can reprice violently is recent. The DeepSeek shock of January 2025, when a cheaper Chinese model wiped roughly a trillion dollars of US AI market value in a single day, including Nvidia’s $588.8 billion single-day loss, the largest in market history, shows how a single efficiency surprise can rerate the whole sector. And note the double edge.
In fact, the same open-weight efficiency that drives the cost deflation of the previous sections, is also the force most likely to compress the prices that section warned about. There is no reason another DeepSeek cannot happen. Pat Gelsinger, the former Intel chief, when asked whether this is a bubble, answered of course.
Antitrust is loading. The cumulative concentration of hyperscaler-lab pairings, Microsoft with OpenAI and Google and Amazon both with Anthropic, is large enough that, per Tech Insider’s reading, the DOJ, FTC, and European Commission are likely to revisit the structure, with a formal investigation plausible by the fourth quarter of 2026. An IPO does not resolve this. It raises the profile of the very arrangements regulators most want to examine.
Company-specific overhangs are real. Sacra flags several that bear directly on Anthropic’s ability to monetize its best work. Its most capable model, previewed as Mythos and codenamed Capybara, has been withheld from general release after it proved able to identify thousands of high-severity software vulnerabilities; the commercial vehicle, Claude Security under Project Glasswing (with partners including Nvidia, AWS, Apple, Google, Broadcom, Microsoft, Cisco, CrowdStrike, and Palo Alto Networks, per The Motley Fool), runs on a deliberately constrained Opus 4.7.
That is a safety decision I think is correct on the merits, and it is simultaneously a self-imposed ceiling on revenue from the company’s most powerful capability.
Add the Pentagon dispute, where Anthropic sued the US government over a designation it viewed as a threat to its revenue, with CFO Krishna Rao testifying that the matter risked cutting 2026 revenue by multiple billions of dollars and where Amodei later publicly apologized for how the company handled the failed talks, and a legal overhang whose verified component is the roughly $1.5 billion authors’ copyright settlement (a larger figure naming the founder personally appears in a single analyst account and is not independently confirmed), and you have a company whose brand safety and its revenue ceiling are the same wall.
The customer-concentration paradox. Recall Claude Code’s billion-dollar ramp. Perera’s sharpest observation is that the company’s fastest-growing product may cannibalize its largest revenue source, because the same agentic coding capability enterprises buy directly can displace the API consumption those enterprises previously paid for. Growth in one column can quietly erode another. We cannot see the net effect, because the filing is confidential.
That phrase keeps recurring, and that is the point. Almost every load-bearing question, the real margin, the realized price per token, the quality of the revenue, the accounting for the SpaceX ramp, the net effect of Claude Code, resolves only when the public S-1 lands.
Until then, the bull and the bear are arguing about a black box.
Who should care, and why
Strip away the spectacle and ask what actually changes downstream. Four things.
For Nvidia and the silicon market, Anthropic is the existence proof. The most important fact in this report for the long-run structure of the industry is that a frontier-class model is being trained and served at scale on Trainium and TPU, not just on Nvidia.
The near-term risk to Nvidia is not revenue, since demand still dwarfs supply, but the long-run margin structure that depends on hyperscalers having no realistic alternative.
As previous sections showed, at rack scale, on a cost-per-workload basis, and on the bandwidth metric that actually governs inference, the alternative now exists. Every chip team at Amazon, Google, and Broadcom is using Anthropic as their proof of concept, and that is worth more to them than the revenue.
For the circular-financing thesis, the IPO is the disclosure event the skeptics have awaited. A public listing forces the first concrete, audited window into a frontier lab’s financials. For two years the bears and bulls have argued about revenue quality with no primary data.
The S-1, once public, will show how Anthropic accounts for hyperscaler-funded revenue, how it books the SpaceX ramp, and what its real, unsubsidized unit economics, including the realized revenue per token that section VII could not pin down, actually look like.
This is the rare case where bull and bear should want the same thing: the numbers. If they are as good as the run-rate suggests, the bubble talk deflates. If they are not, better to know now.
For enterprise buyers, the public-company transition changes the vendor relationship. Public companies optimize for quarterly margins in ways private ones do not.
The inference-cost deflation that has made Claude cheaper every year was partly funded by patient private capital. A public Anthropic, answerable to shareholders, may price differently, and may be less willing to pass the full token-cost decline through to customers.
For anyone building production systems on Claude, that is a planning input, not a panic, and one more argument for the multi-provider architectures that open-weight alternatives like DeepSeek and Llama keep making viable.
For the private markets and the broader economy, the drain is unclogging, for better and worse. Three trillion-dollar IPOs in a hundred days will pull enormous capital into public AI equities and force index providers to confront new inclusion rules for companies this large arriving this fast.
If the debuts go well, they validate the cycle and pull more capital in.
If they go poorly, three of the largest IPOs in history repricing in quick succession is exactly the event that turns a capex bubble into a capex correction, with the roundtripping amplifying the move down just as it amplified it up.
The labor question rides alongside: tech layoffs passed 115,000 through May 2026, with Meta, Amazon, and Snap citing AI, even as the Yale Budget Lab found no significant change yet in the occupational mix of high-exposure jobs. The same plumbing runs in both directions, and so does the narrative.
“What I see is this smooth exponential line. And that march has just been constant.”
Dario Amodei · Anthropic CEO, at Davos 2026, on why he discounts the cycle of hype and bubble talk (Rest of World)
Set against that, Nvidia’s Huang, who has said publicly he disagrees with almost everything Amodei says, dismisses the doomier predictions as the product of a CEO God complex. T
wo of the most important people in the industry cannot agree on whether it is reshaping labor, let alone whether it is a bubble. The IPOs will not settle that. They will only price it.
The bottom line
Here is what I actually think, stated plainly, with the byline caveat from the top still standing.
Anthropic is, by the public evidence, the best-positioned of the three companies going public this summer. It has the cleanest revenue mix, the leanest cost structure, the most credible margin-expansion story, and a genuinely differentiated three-silicon strategy that is reshaping the hardware layer beneath the entire industry.
The physics say a seventy-seven-percent gross margin is plausible rather than fanciful; the comps of previous parts say a trillion-dollar valuation is mid-pack rather than mad; the insider behavior at the tender offer and the speed of the run-rate point the same way. If forced to rank the three debuts on fundamentals rather than spectacle, Anthropic would be first.
And the entire case rests on three things we cannot yet verify and one we can. We cannot verify the real gross margin, the realized price per token, or the accounting behind the Q2 profitability claim, because the filing is confidential.
What we can verify is that the company is being valued at over a trillion dollars on exactly those unverified figures, inside a capital structure that critics, with a strong historical analogy, compare to the vendor financing that deepened the last great technology crash.
That is not a contradiction. It is the trade. The bull is betting the black box is full of seventy-seven-percent-margin, organically demanded, durably embedded enterprise revenue, with a cost-to-serve falling faster than price.
The bear is betting it is full of forty-five-percent-margin revenue, propped by a circular capital loop, with open-weight competition dragging price down to meet cost, in a demand environment that is just starting to flinch.
The public S-1, fifteen days before the roadshow, opens the box. Everything before then, including the trillion-dollar valuation the market has already assigned, is a wager placed in the dark.
The vertical is real. The loop is real. The physics is real. The only honest position, until the numbers are public, is to hold all three in view at once and refuse to pretend the box is open when it is still shut.
Disclosures, statements, and the safety architecture
What follows is the verifiable record behind the analysis: what was actually filed and said, on the record, by whom, and when. None of it is the confidential S-1’s financials, which remain sealed. Where a claim rests on a single source, it is marked.
The filing, precisely
Anthropic confirmed on June 1, 2026 that it had confidentially submitted a draft Form S-1 to the SEC, in an announcement made under Rule 135 of the Securities Act, a rule that by design states only that a filing exists: the number of shares and the offering price are explicitly undetermined, and the offering remains subject to market conditions.
Because the submission is confidential, Anthropic has disclosed no audited revenue, no margin, and no risk factors; under SEC rules for emerging growth companies those become public only about fifteen days before a roadshow.
The filing came four days after a cluster of disclosures on May 28, 2026: the close of a $65 billion Series H at a $965 billion post-money valuation, confirmation that run-rate revenue had crossed $47 billion earlier in May, and the release of Claude Opus 4.8. Multiple outlets place the listing target in an October 2026 window, above $1 trillion if markets cooperate.
One revealing side event: in May 2026 Anthropic warned about unauthorized transfers of its shares, naming several platforms selling unapproved, SPV-backed pre-IPO tokens and cautioning that such instruments may carry limited or no legal value.
Tokenized Anthropic and OpenAI pre-IPO products reportedly fell 34 to 40 percent within days, per Bitcoin.com, a vivid illustration of demand for liquidity running far ahead of authorized supply, the same pressure visible in the earlier employee tender.
What the executives said, on the record
The single most important primary statement is Amodei’s own. At the Code with Claude developer conference in San Francisco on May 6, 2026, he said the company had planned for roughly tenfold annual growth but instead saw, in his words, eighty-fold annualized growth in the first quarter, which he gave as the direct cause of the company’s compute shortages, promising to pass that capacity to developers as fast as it could be brought online, per CNBC.
“In Q1 2026, we saw 80x annualized growth per year in revenue and usage.”
Dario Amodei · Anthropic CEO, Code with Claude, San Francisco, May 6, 2026 (CNBC)
That exuberance has a hard floor, and Amodei has named it precisely. On Dwarkesh Patel’s podcast in March 2026 he walked through the arithmetic of his own ruin: if he committed to a trillion dollars a year of compute in 2027 and revenue arrived even at $800 billion rather than the trillion he is extrapolating, then in his phrase there is “no force on earth” that could stop the company from going bankrupt.
It is the clearest admission any frontier-lab chief executive has made that the whole edifice is a bet on a growth rate continuing, and that the bet is existential. He has also said publicly that the industry may be near the end of the exponential.
The operator behind the IPO is CFO Krishna Rao, who joined in 2024 as the company closed its Series D at roughly $250 million in run-rate revenue, and who previously guided Airbnb’s IPO. Rao calls compute the lifeblood of the business and says he spends 30 to 40 percent of his time on it.
He has named the three risks that would push Anthropic toward the bottom of its growth cone rather than the top: enterprise diffusion failing to keep pace with model capability, scaling laws unexpectedly flattening, and competition eroding margins, per his interview with YourStory.
In a court filing around March 2026 Rao stated under oath that the company had brought in revenue exceeding $5 billion to date, the figure critics such as Ed Zitron use to argue the later profitability claim was flattered by the timing of the SpaceX compute discount.
“The compute that we procure is the lifeblood of our business.”
Krishna Rao · Anthropic CFO, who previously led Airbnb’s IPO (YourStory)
Talent, culture, and the organization
Anthropic’s defining operational claim is talent retention under siege. When Meta made aggressive offers across the frontier labs, Anthropic reportedly lost only two researchers where rivals lost dozens, a result Rao attributes to a culture the company describes as talent density over talent mass.
All seven co-founders remain, as does the vast majority of the first thirty employees; every hire must clear a culture interview; and Amodei addresses the entire company every two weeks and takes unscripted questions, per YourStory.
In February 2026 Anthropic opened a Bengaluru office, calling India its second-largest market for Claude.
The safety architecture, which is also a revenue constraint
Anthropic governs releases through its Responsible Scaling Policy, first published in September 2023 and rewritten as Version 3.0, effective February 24, 2026, which introduced Frontier Safety Roadmaps and Risk Reports that quantify risk across deployed models.
The policy uses AI Safety Levels modeled on biosafety: ASL-2 is the current baseline; ASL-3, which Anthropic first activated alongside Claude Opus 4 in May 2025, adds hardened weight security and a narrow set of deployment limits aimed at CBRN misuse; ASL-4 is reserved for models posing major national-security risk or capable of autonomous AI research.
At Opus 4’s launch, chief scientist Jared Kaplan said the model gave novices a “significantly greater” uplift toward building biological weapons than a search engine or prior models, per TIME.
The clearest case of safety capping revenue is Claude Mythos. Announced as a preview on April 8, 2026, Mythos autonomously discovered, and wrote working exploits for, thousands of zero-day vulnerabilities across major operating systems and browsers, capability Anthropic judged too dangerous for general release, placing it at or near the ASL-3 cyber threshold per the Cloud Security Alliance.
The commercial vehicle, Claude Security under the Glasswing program, runs a deliberately constrained model and carries 90-day reporting commitments.
Anthropic has also published a Sabotage Risk Report for Opus 4.6 and, in February 2026, an internal Noncompliance Reporting and Anti-Retaliation Policy giving employees channels to flag potential violations.
Each of these is a decision that is defensible on its safety merits and simultaneously a self-imposed ceiling on the revenue the company’s most powerful capabilities could earn.
The model record, and what Anthropic does not disclose
The Claude lineage behind the revenue is precise and public at the capability level:
Opus 4.5 (November 24, 2025) shipped a 200k-token context window and a 64k-token thinking budget, with up to 65 percent fewer tokens on long-horizon coding;
Opus 4.6 (February 2026) added a 1M-token context in beta and led Terminal-Bench 2.0 and Humanity’s Last Exam; Sonnet 4.6 followed on February 17, 2026;
Opus 4.7 was independently rated the most EU-AI-Act-compliant model by the testing firm Aithos;
and Opus 4.8 (May 28, 2026) carries a 1M-token context with cross-session memory for multi-day work.
Critically, none of these system cards disclose the one thing an analyst most wants: parameter counts, layer counts, or whether the models are dense or mixture-of-experts.
Anthropic publishes capability and safety evaluations in exhaustive detail and keeps the architecture itself sealed, which is exactly why the inference unit-economics had to be built from silicon specifications and first principles rather than from any disclosed model size.

The data, at a glance
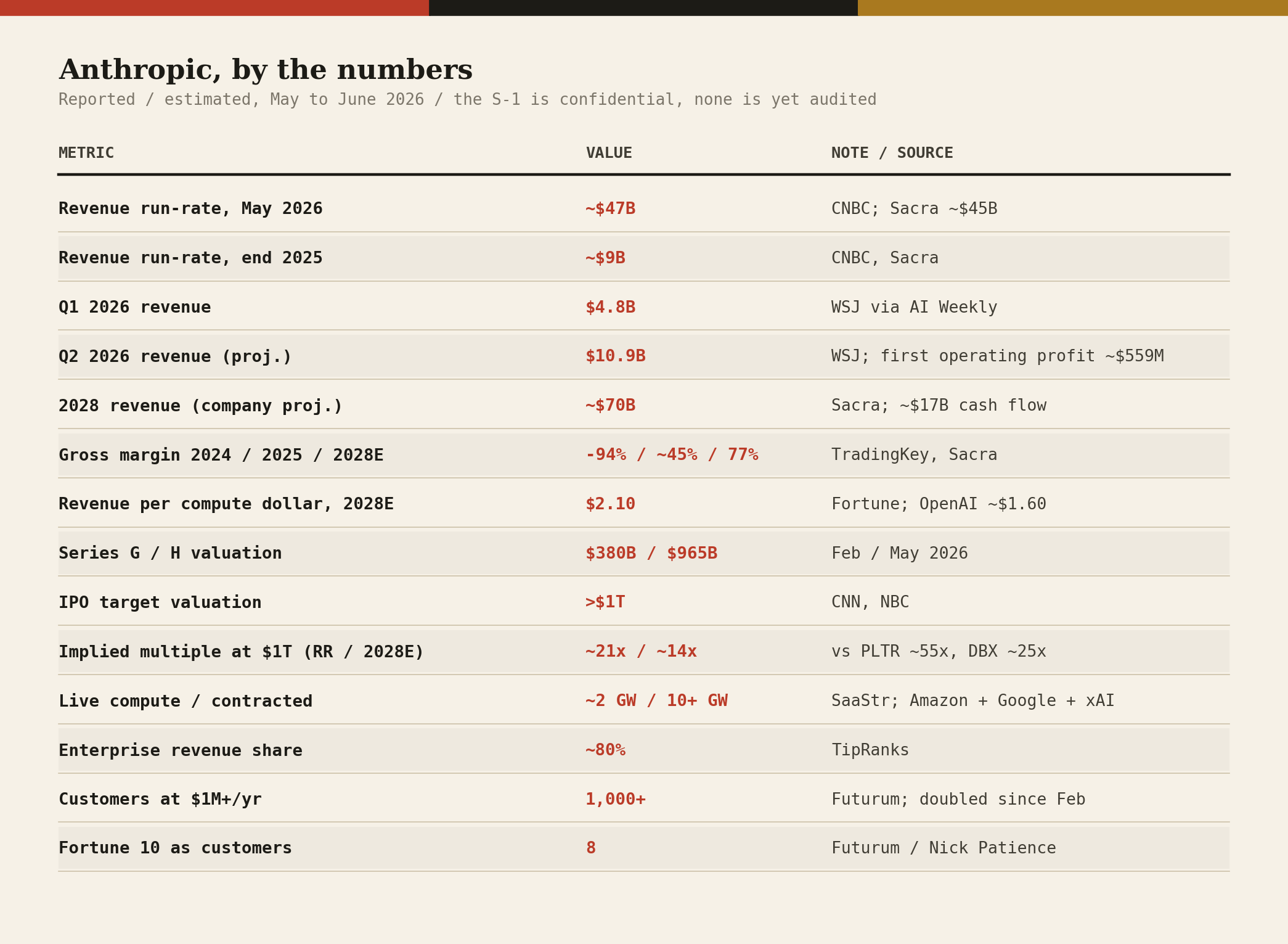


Methodology. The cost-to-serve and gross-margin-bridge figures in section VII are illustrative models built from published silicon benchmarks and stated assumptions, not Anthropic disclosures; they are intended to show order of magnitude and mechanism, not to report the company’s actual numbers, which are confidential.
Revenue, valuation, and capacity figures throughout are reported, estimated, or projected by the cited third parties. Where sources conflict (for example, run-rate near $45B vs $47B, or Trainium3 availability dates), the range is given in text.
Sourcing. Reporting and analysis from CNBC, CNN, NBC News, Axios, Reuters, the Wall Street Journal (via AI Weekly and Sacra), Bloomberg, TechCrunch, Datacenter Dynamics, Yahoo Finance, Fortune, Benzinga, The Motley Fool, Futurum, Investing.com, and Business Standard; infrastructure, inference, and financial analysis from Sacra, PitchBook, Global Data Center Hub, Tech Insider, TradingKey, SaaStr, BlockEden, Tool Directory, IEEE ComSoc, IntuitionLabs, Introl, Inworld, GMI Cloud, Spheron, CloudRift, multiples.vc, and an arXiv study on token-price evolution; silicon specifications from Tom’s Hardware, Oplexa, Introl, and Awesome Agents; benchmark data from Nvidia InferenceMax; company statements from Anthropic, xAI, and Databricks; commentary from Ed Zitron, Derek Thompson, Shanaka Anslem Perera, and the named analysts (Rasgon / Bernstein, Ives / Wedbush, Cahn / Sequoia, Duberstein / Motley Fool, Patience / Futurum).
Disclosure and limits. All financial figures are reported, estimated, or projected; none are drawn from a publicly available audited filing, because Anthropic’s S-1 remained confidential as of the filing date. Nothing here is investment advice. This is analysis, not a recommendation.