
System Design Simplified: A Beginner's Guide to Everything You Need to Know (Part 2)
Master the Basics of System Design with Clear Concepts, Practical Examples, and Essential Tips for Beginners.


System Design Simplified: A Beginner's Guide to Everything You Need to Know (Part 2)
Welcome to the second part of our System Design Simplified series! In this section, we’ll dive deeper into the essential building blocks of designing scalable, efficient, and reliable systems. As your systems grow in complexity, developers face new challenges in maintaining performance, managing increased load, and ensuring fault tolerance and availability. To meet these challenges, it’s crucial to understand the fundamental concepts that underpin system design, which are key to building systems that can handle millions of users, high traffic, and the ever-evolving demands of modern applications.
In this guide, we’ll explore critical aspects of system design, including Caching Mechanisms, the State of the Envelope and finally, the CAP Theorem. These concepts lay the groundwork for architecting systems that not only scale efficiently but can also maintain high availability, consistency, and data integrity even during peak traffic and failures.
Throughout this part, we will break down these principles in a way that’s accessible, ensuring you understand how to apply them in real-world situations. Whether you're designing large-scale distributed systems, optimizing performance, or making decisions about state management, these foundational concepts will empower you to make informed choices that directly impact the robustness and scalability of your systems.
By mastering these concepts, you’ll be equipped to build systems that perform well under pressure, maintain seamless user experiences, and are designed to grow over time. This will allow you to handle both unpredictable traffic spikes and long-term scaling challenges without compromising performance or reliability. Let’s jump into these critical topics and start building a deeper understanding of how they contribute to robust system design.
6. Caching Mechanisms: An Overview
Caching is actually one of the most effective techniques in modern computing to improve system performance and scalability. At its core, caching involves storing copies of data in a temporary storage layer, allowing faster access to frequently used or computationally expensive information. By reducing the need to fetch data from a slower source, such as a database or remote API, caches significantly reduce latency, enhance user experience, and decrease the load on backend systems.
The importance of caching spans across various domains. In web applications, for instance, caching can serve static assets like images, CSS, and JavaScript files to speed up page loads. In databases, query results are cached to avoid repeatedly executing complex operations. For distributed systems, caching helps mitigate bottlenecks by enabling quicker data retrieval across nodes.
Caching, however, is not without challenges. Managing stale data, choosing appropriate eviction policies, and determining what data to cache are critical decisions that influence the effectiveness of a caching strategy. Over-caching can lead to memory overuse, while under-caching may fail to deliver the desired performance benefits.
To address these challenges, modern caching tools and techniques have evolved, offering diverse options for developers. Among the most widely used caching systems are Redis and Memcached, each tailored to different use cases. Additionally, various strategies like cache invalidation, TTL-based expiration, and the combination of browser-side and server-side caching help maintain data consistency and optimize performance.
With this understanding, let’s delve into specific caching tools and strategies to see how they address different aspects of performance optimization.
Redis Deep Dive
Redis, short for Remote Dictionary Server, is a cornerstone of modern computing, known for its unmatched speed and versatility. At its heart, Redis is an in-memory data structure store that can act as a database, cache, and message broker. But calling it just a key-value store would do it a disservice; Redis is much more. With its ability to handle advanced data types like hashes, lists, sets, sorted sets, bitmaps, hyperloglogs, and even geospatial data, Redis has redefined what a caching layer or in-memory database can achieve.
Operating entirely in memory, Redis delivers lightning-fast read and write operations with sub-millisecond latency. This speed is crucial for applications that require real-time responses, such as live dashboards, gaming leaderboards, or instant messaging systems. However, Redis doesn't just stop at being fast—it also provides robust features that ensure data persistence, flexibility, and reliability.
A Glimpse into Redis's Key Features
Redis's magic lies in how it balances simplicity with powerful functionality. Its features cater to diverse needs, making it a go-to tool for developers building high-performance systems.
Blazing Performance
At its core, Redis is designed for actual speed. By keeping all data in memory, it avoids the latency of disk access, making it capable of handling millions of requests per second. Whether you're caching user session data, storing frequently accessed database queries, or building a real-time leaderboard, Redis ensures near-instantaneous responses.Persistence: Beyond a Simple Cache
While many think of caching as ephemeral, Redis takes it a step further by offering optional persistence. This makes Redis suitable not just as a cache but also as a durable data store. Developers can choose between:RDB Snapshots: Periodic snapshots of the dataset, suitable for disaster recovery.
AOF (Append-Only File): A detailed log of write operations, enabling fine-grained recovery.
These options ensure that your data isn't lost even if the system crashes, a feature that sets Redis apart from simpler in-memory systems like Memcached.
Advanced Functionality: Redis as a Swiss Army Knife
Redis isn’t just fast—it’s also very smart. Its advanced features allow developers to solve complex problems efficiently:Lua Scripting: Execute multiple commands atomically using custom scripts, reducing network overhead.
Transactions: Group commands into atomic operations, ensuring data integrity.
Pub/Sub Messaging: Build real-time systems like chat applications or notifications with its built-in publish/subscribe model.
Geospatial Queries: Handle location-based data effortlessly, powering applications like delivery tracking or location-based searches.
Redis Streams: Manage log-like data structures for event sourcing or real-time analytics.
Smart Eviction Policies
Managing memory effectively is crucial in caching, and Redis provides a suite of eviction policies to control how old data is removed when memory is full. Policies like Least Recently Used (LRU) and Least Frequently Used (LFU) ensure that the cache holds only the most relevant data, optimizing performance.
Real-World Applications of Redis
Redis shines in scenarios where speed and reliability are non-negotiable, like:
Real-Time Analytics: For applications like live dashboards or instant insights, Redis aggregates and serves data at lightning speed.
Gaming Leaderboards: Using sorted sets, Redis excels in creating dynamic, real-time leaderboards that can handle thousands of updates per second.
Session Management: With its TTL (Time-to-Live) feature, Redis ensures that user sessions expire gracefully, making it ideal for authentication systems.
Distributed Locks: In distributed systems, Redis's ability to implement fast and reliable locks is invaluable for coordinating tasks across multiple services.
Scaling and Integration: Redis in the Modern Ecosystem
Redis is designed to grow with your needs. Its clustering capabilities allow data to be sharded across multiple nodes, providing horizontal scalability and fault tolerance. Whether you’re managing a small application or a global-scale system, Redis adapts seamlessly.
Moreover, Redis boasts a rich ecosystem with libraries and integrations for nearly every programming language. This universal compatibility makes it a natural choice for developers working across diverse platforms and technologies. From Python and JavaScript to Go and Java, Redis’s simple API and client libraries make integration effortless.
Memcached Overview
Memcached is a time-tested in-memory caching system designed to enhance application performance by reducing database load. Built for speed and simplicity, it operates as a lightweight solution, storing frequently accessed data in memory to ensure rapid retrieval. Its straightforward design has made it a favorite for developers who need a reliable caching layer without the complexity of more feature-rich systems.
Memcached focuses exclusively on caching, which allows it to deliver exceptional performance with minimal overhead. By temporarily storing data like session information, rendered HTML fragments, or API responses, it significantly improves application response times and scalability.
Key Features
Speed and Efficiency
Memcached’s lean architecture ensures sub-millisecond response times. Its simplicity minimizes resource usage, making it ideal for high-throughput applications.Scalable Design
With its distributed nature, Memcached scales horizontally by spreading data across multiple nodes using consistent hashing. This makes it well-suited for growing systems and large-scale workloads.Simple Expiration and Eviction
Developers can set a Time-to-Live (TTL) for cached items, ensuring automatic expiration of stale data. When memory fills up, older or less-used items are evicted, maintaining efficient use of resources.
Use Cases and Limitations
Memcached excels in read-heavy workloads, such as:
Session Storage: Quickly retrieves user session data to reduce database queries.
HTML Fragment Caching: Speeds up page loads by caching pre-rendered content.
API Response Caching: Handles frequent requests without taxing backend systems.
However, it lacks data persistence and advanced features like complex data structures, making it less versatile than systems like Redis. Additionally, data is lost if the server restarts, so Memcached is best for temporary caching needs.
Why Use Memcached?
For applications with high read-to-write ratios or simple caching needs, Memcached provides a robust, fast, and easy-to-deploy solution. Its focus on simplicity allows it to deliver reliable performance without unnecessary complexity, making it a go-to tool for developers optimizing application speed.
Cache Invalidation Strategies
Caching is a powerful tool for accelerating applications and reducing the load on underlying systems, but it comes with a significant challenge: ensuring data consistency. When cached data becomes stale or incorrect, it can lead to errors, outdated information, and a poor user experience. Cache invalidation—the process of removing or updating outdated data in a cache—is therefore critical to maintaining a balance between performance and accuracy. Let's explore the most common strategies for cache invalidation and how they address this challenge.
1. Time-Based Expiration (TTL)
One of the simplest and most widely used cache invalidation strategies is to assign a Time-to-Live (TTL) to cached data. Each item in the cache is automatically removed after a predefined duration, ensuring that stale data is not served indefinitely.
Advantages: TTL is straightforward to implement and requires minimal application logic. It provides a balance between freshness and performance, especially for data that changes at predictable intervals.
Limitations: Time-based expiration doesn’t account for unexpected changes in the underlying data. For example, if inventory levels drop rapidly or user profile details are updated, the cache may still serve outdated data until the TTL expires.
2. Write-Through Cache
In a write-through strategy, every write operation updates both the cache and the underlying datastore simultaneously. This ensures that the cache always contains the most up-to-date data.
Advantages: This strategy guarantees data consistency between the cache and the datastore. It’s particularly useful for applications where reads significantly outnumber writes.
Limitations: Write-through caching can introduce latency during write operations since both the cache and datastore must be updated together. For write-heavy workloads, this may impact performance.
3. Write-Around Cache
With a write-around cache, data is written directly to the datastore, bypassing the cache entirely. Cached data is only updated during a subsequent read operation.
Advantages: This approach reduces latency for write operations, making it suitable for write-heavy scenarios.
Limitations: The primary drawback is that it increases the likelihood of cache misses. Newly written data won’t appear in the cache until it’s explicitly requested, which can degrade read performance.
4. Write-Back Cache
In a write-back strategy, data is first written to the cache and then asynchronously persisted to the underlying datastore. This approach prioritizes write performance by deferring persistence operations.
Advantages: Write-back caching is highly efficient for write-intensive applications. It reduces the write latency significantly and allows batch updates to the datastore.
Limitations: The asynchronous nature introduces a risk of data loss if the cache fails before the data is persisted to the datastore.
5. Manual or Event-Driven Invalidation
This strategy involves explicitly invalidating or updating cache entries based on specific triggers, such as a user action or a business event.
Advantages: Manual invalidation provides precise control over the cache, ensuring that stale data is removed immediately after a relevant change. It’s ideal for applications with unpredictable or event-driven updates.
Limitations: Implementing this strategy requires more complex logic and careful coordination between the application and cache, increasing development effort and the risk of bugs.
Browser vs. Server-Side Caching
Caching can be applied at multiple layers of a system, with browser caching and server-side caching being the most common. Both approaches have distinct advantages and challenges, and understanding their roles can help you design a comprehensive caching strategy.
Browser Caching
Browser caching focuses on storing static resources like HTML, CSS, JavaScript, and images on the user's device. This reduces redundant network requests and speeds up page loads.
Mechanism: Developers configure browser caching using HTTP headers like
Cache-Control,ETag, andExpires. These headers instruct browsers on how long to store resources and when to check for updates.Benefits: By leveraging the user's device for storage, browser caching significantly reduces server load and enhances user experience through faster page loads.
Challenges: Cache invalidation can be tricky. For instance, if an updated JavaScript file is not fetched due to cached versions, it can cause application errors. Cache-busting techniques, like appending version numbers to resource URLs, are often necessary.
Server-Side Caching
Server-side caching, on the other hand, stores data closer to the application logic. Tools like Redis or Memcached are commonly used to cache database query results, computed data, or API responses.
Mechanism: Unlike browser caching, server-side caching is controlled programmatically, allowing dynamic and granular cache management tailored to the application’s needs.
Benefits: Server-side caching reduces the load on databases and other backend systems, improving performance and scalability for high-traffic applications.
Challenges: Ensuring consistency between the cache and the datastore requires careful management. Memory limits and eviction policies must also be considered to avoid running out of cache space.
Combining Browser and Server-Side Caching
To achieve optimal performance, many systems combine browser and server-side caching. Browser caching handles static assets, reducing the need for repetitive network requests, while server-side caching accelerates access to dynamic or frequently used data. For example:
Browser caching can store CSS and JavaScript files to improve front-end performance.
Server-side caching can hold user session data or API results, reducing latency for backend operations.
By understanding and implementing these caching mechanisms and strategies, you can create systems that deliver not only high performance but also reliability and data consistency. Whether leveraging Redis for real-time data or Memcached for high-speed lookups, selecting the right tools and invalidation strategies will enhance the efficiency and user experience of your applications.
7. Back-of-the-Envelope Estimation
Back-of-the-envelope (BOTE) estimation is an essential practice for system design and capacity planning. It provides a quick, high-level framework for assessing the feasibility and scalability of a solution without requiring detailed analysis. While not precise, these calculations are invaluable in identifying potential bottlenecks, resource requirements, and overall system viability. BOTE estimations are particularly useful in the early stages of project planning, helping engineers make informed decisions before investing in detailed architecture or resource allocation.
Here’s a deep dive into the key components of BOTE estimation:
1. Load Estimation: Understanding System Demands
Defining the Load
Load estimation focuses on quantifying how much work the system needs to handle. This includes user interactions, API requests, background processes, and batch jobs. The load determines the scale of infrastructure required and is foundational for planning other resources like compute, storage, and bandwidth.
Key Factors to Consider:
Number of Users: Break down the user base into categories like daily active users (DAU), monthly active users (MAU), and peak concurrent users. This segmentation helps gauge both steady-state and peak load scenarios.
Request Frequency: Analyze how often users interact with the system. For example, how many API requests, page views, or database queries occur per user per session?
Peak Traffic Periods: Identify specific times of high activity, such as promotional sales, live events, or end-of-month reporting. Peak periods define the maximum capacity your system must support.
Concurrency: Estimate the number of simultaneous interactions. For example, how many users are likely to upload files, stream videos, or browse products at the same time?
Example Calculation:
Consider a video streaming platform:
User Base: 10 million active users daily.
Usage Pattern: Each user streams 3 videos/day, and each video requires 10 HTTP requests (e.g., metadata, video chunks, etc…).
Daily Requests: 10 million × 3 × 10 = 300 million requests.
Requests Per Second (RPS): 300 million ÷ 86,400 seconds = ~3,472 RPS.
This calculation provides a baseline for designing infrastructure capable of handling the estimated traffic. Add a safety margin (e.g., 20–30%) to accommodate unexpected spikes.
2. Storage Estimation: Planning for Data Growth
Anticipating Storage Needs
Storage estimation involves assessing the data volume your system will generate, process, and retain. This includes structured data (databases), unstructured data (media files), logs, and backups. Effective storage planning ensures that your system remains operational and scalable as data grows.
Key Considerations:
Data Size per Object: Calculate the size of individual entities like database records, log entries, or media files.
Data Volume: Multiply the size of each object by the number of objects generated over time.
Growth Rate: Factor in how quickly data volume will increase due to new users, features, or usage patterns.
Replication and Backups: Include additional storage for redundancy (e.g., RAID, replication across nodes) and backup copies.
Example Calculation:
For a social media platform:
User Activity: Each user generates 500 KB of data/day (posts, comments, media uploads).
Daily Storage: 10 million users × 500 KB = 5 TB/day.
Yearly Storage: 5 TB × 365 days = 1,825 TB (~1.8 PB).
Replication: With 3x replication for fault tolerance, storage needs = 1.8 PB × 3 = 5.4 PB/year.
This estimation helps determine whether to use local storage solutions, cloud-based options, or distributed systems like HDFS or Amazon S3.
3. Resource Estimation: Compute and Memory Requirements
Ensuring Adequate Resources
Resource estimation focuses on understanding the CPU, memory, and other computational resources required to handle the system’s load efficiently.
Compute Requirements:
Estimate the average processing time per request. For instance, an API call might take 50 ms of CPU time.
Multiply the processing time by the expected number of requests per second to determine total compute needs.
Divide by the capacity of a single CPU core. If one core can handle 20 requests per second, a system processing 3,472 RPS would need 3,472 ÷ 20 = ~174 cores.
Memory Requirements:
Calculate memory usage for storing session data, temporary in-memory processing, or caching.
Factor in additional memory for system overhead, such as operating system processes and application frameworks.
Example Calculation:
For a chat application:
User Sessions: Each session consumes 10 KB of memory.
Concurrent Users: With 1 million concurrent users, total memory = 1 million × 10 KB = 10 GB.
Redundancy: Add memory for redundancy and other processes. With 16 GB/server, you’d need at least 1 server for sessions plus more for handling spikes and redundancy.
4. Network Bandwidth Estimation: Supporting Data Transfer
Quantifying Bandwidth Requirements
Network bandwidth estimation ensures that your system can handle the volume of data transfer required without significant latency or bottlenecks.
Key Factors:
Data Per Request: Determine the size of data exchanged for each operation (e.g., API calls, file uploads). For video streaming, this might include metadata (50 KB) and video chunks (2 MB/second).
Requests Per Second: Multiply data size by the number of requests per second to calculate throughput requirements.
Peak Bandwidth: Account for periods of maximum traffic to avoid network congestion.
Example Calculation:
For a file-sharing platform:
Data Per Download: Each file is 10 MB.
Concurrent Downloads: 1,000 users downloading simultaneously = 1,000 × 10 MB = 10 GB.
Peak Traffic: If peak usage doubles to 2,000 concurrent downloads, bandwidth must scale to 20 GB.
This estimation helps you decide whether to deploy a content delivery network (CDN), optimize compression, or increase cloud bandwidth.
Bringing It All Together
Iterative Refinement
Back-of-the-envelope estimations are iterative. Start with high-level numbers, then refine as you gather more detailed requirements and metrics. For example, after estimating storage needs, you may realize that compression can reduce the data size, or that cache can offload a portion of the load from your backend systems.
Trade-Offs and Prioritization
BOTE estimations also help identify trade-offs. For instance, reducing latency might require higher memory usage or increased bandwidth. By quantifying these trade-offs early, you can prioritize investments in infrastructure and optimization.
Example Use Case:
When designing a real-time messaging platform:
Load Estimation: 5 million active users sending 2 messages/second.
Storage Estimation: 500 bytes/message, replicated 3 times = ~15 TB/year.
Resource Estimation: 10 KB/session for 1 million concurrent users = 10 GB memory.
Network Bandwidth Estimation: 1 KB/message × 2 messages × 5 million users = ~10 GB/second during peak.
By breaking down each aspect, you can design systems that are not only feasible but also efficient and scalable. Back-of-the-envelope calculations act as the first step toward informed decision-making, ensuring your architecture can meet its demands while remaining cost-effective.
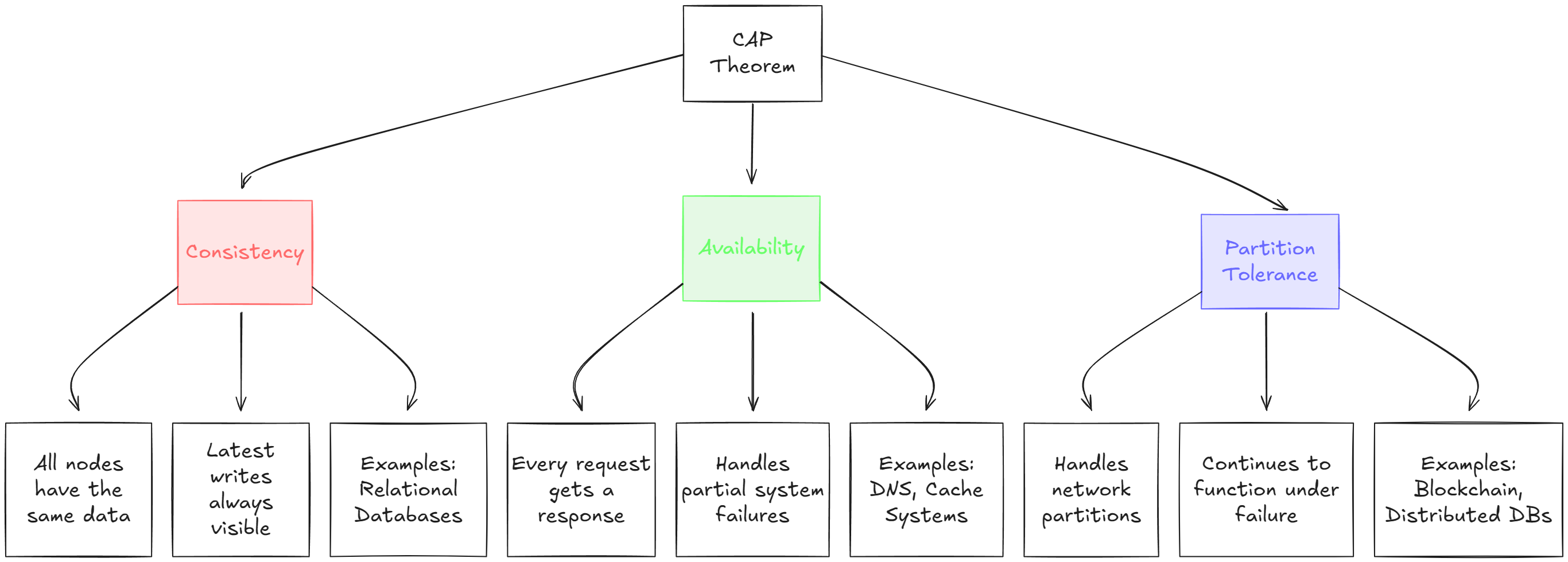
8. CAP Theorem : Real-World Trade-offs and Use Cases
Making Smart Trade-offs in Distributed Systems
The CAP Theorem, also known as Brewer’s Theorem, is one of the most well-known and fundamental principles in the world of distributed systems. At its core, the theorem explains that in any distributed system, you’re forced to choose between three essential properties: Consistency, Availability, and Partition Tolerance. It asserts that no distributed system can guarantee all three of these properties at once—you can only have two out of the three.
In simpler terms, this means that in the real world, designing distributed systems involves making tough choices about which of these properties are most important based on the specific needs of your application and users. Understanding the CAP Theorem is a game-changer because it shapes the behavior, reliability, and scalability of the systems we design. So let’s dive deep into each of these properties, explore their implications, and break down how they manifest in real-world distributed systems.
Understanding the Core Properties
Before we discuss the trade-offs, let's first understand each of the three core properties that make up the CAP Theorem.
1. Consistency (C): Ensuring a Single, Unified View of Data
When we talk about Consistency, we’re referring to the idea that every node in a distributed system should have the same data at any given point in time. Imagine a system with multiple copies of data distributed across various servers. Consistency guarantees that after a write operation (like updating a user’s email address), every node will have the exact same data, and all subsequent reads will reflect that most recent change.
For example, in a consistent system, if a user updates their profile by changing their email address, the system ensures that all other users querying that profile will immediately see the updated email.
Think of Consistency as keeping all your files synchronized across multiple devices: if you update a file on one device, that update appears on all devices instantly.
But here's the challenge: Consistency often comes at a cost. To achieve it, the system may need to synchronize data across all nodes in real-time, which can lead to delays or conflicts—especially in the event of network partitions. In the case of large-scale distributed systems, maintaining strict consistency can make the system less responsive or slower.
2. Availability (A): Keeping the System Responding No Matter What
Availability guarantees that every request (whether a read or write) will receive a response, even if some of the nodes are temporarily unreachable. In simpler terms, the system never fails—it’s always on and always responsive.
For example, imagine a distributed database with multiple copies of data. Even if some of the copies are temporarily unavailable (due to network failure or a server crash), the system will continue to respond to requests with the available data.
Consider a storefront website during a Black Friday sale. When users rush to check out, they expect the site to be operational without interruption, even if some backend servers become unavailable due to the massive traffic spike. The site may temporarily serve stale data (e.g., showing an item as in stock even if it’s actually out of stock) to ensure availability during these high-traffic moments.
The trade-off with availability, however, is that the data returned in the event of a partial failure might not be the most recent or accurate. You might end up with stale data or outdated responses, which could affect the user experience if users expect the most up-to-date information.
3. Partition Tolerance (P): Ensuring the System Can Handle Network Failures
Partition Tolerance is arguably the most important property in large-scale distributed systems, particularly for systems deployed over unreliable networks (like the internet). It refers to the system’s ability to continue operating correctly even if some nodes can’t communicate with others due to network failures.
Think about this: in a large system spread across multiple data centers (possibly across regions or continents), network failures or latencies are inevitable. Partition Tolerance ensures that the system can still function even if some parts of it are disconnected or isolated from the rest.
For instance, imagine two regions of a globally distributed application (one in North America and the other in Europe). If a network partition occurs between the two regions, Partition Tolerance ensures that the system doesn’t break down. Users in the European region can still make requests, even though they might not have immediate access to data from the U.S.-based nodes.
Without Partition Tolerance, a failure or delay in communication between nodes could cause parts of the system to crash or become unresponsive, making the entire system unreliable. This is a major issue in distributed systems where uptime and fault tolerance are critical.
The Trade-offs: Choosing Two Properties at a Time
Now that we’ve understood the three key properties—Consistency, Availability, and Partition Tolerance—we can discuss how they interact in the real world. According to the CAP Theorem, you can’t have all three properties at once. You must choose two, and the third will be sacrificed.
This is where the real decision-making happens. Let’s look at the three possible combinations and the scenarios where each might be most appropriate:
1. Consistency + Availability (CA): A Strong but Fragile System
In the CA model, the system guarantees Consistency and Availability, but it sacrifices Partition Tolerance. In other words, the system ensures that all data is consistent across nodes and will always respond to requests—but it won’t work properly during a network partition. This means that if a network failure occurs, the system may stop functioning until the partition is resolved.
When to use CA? This is ideal for smaller, centralized systems with reliable networks where partitions are rare. Think of systems that don’t involve large-scale distributed components, like a single-node database or small apps running in a trusted, localized environment.
Example: A traditional relational database like MySQL might fit this model if you’re running it on a single node with no need for network partitioning.
Challenges: In the event of a network partition, a CA system must either fail or abort operations to maintain consistency, which can cause downtime.
2. Consistency + Partition Tolerance (CP): Integrity Over Availability
In the CP model, the system guarantees Consistency and Partition Tolerance, but it sacrifices Availability. This means that during a network partition, the system will prioritize data consistency (making sure that the data remains synchronized) even if that means rejecting requests until the partition is resolved. In essence, the system ensures no stale data is read, but it might become temporarily unavailable during network failures.
When to use CP? This is ideal for systems where data integrity is critical, and you can tolerate temporary downtime. For example, financial systems, banking applications, or payment processing systems rely on ensuring that transactions are complete and consistent, even if that means temporarily rejecting some user requests.
Example: Systems like HBase or Zookeeper follow a CP approach where data integrity is paramount, and availability can be sacrificed for consistency during network issues.
Challenges: In CP systems, users might face downtime during partitions. This could be problematic for real-time services that require constant access.
3. Availability + Partition Tolerance (AP): Always On, Even With Inconsistent Data
The AP model ensures that the system will always respond to requests, even during a network partition. This guarantees that the system is available and partition-tolerant, but it might return inconsistent data because different nodes may not have synchronized the latest writes.
When to use AP? This is ideal for systems where it’s crucial to keep running at all costs—even if some data may be out of sync for a while. For example, social media platforms, e-commerce sites, and real-time messaging apps often prioritize availability and partition tolerance over strict consistency.
Example: Cassandra is an example of an AP system, allowing for always-available writes and reads—even if some replicas are out of sync temporarily.
Challenges: The main trade-off is that data returned from different nodes may be inconsistent. This could mean users see outdated information temporarily, leading to potential confusion or issues with user experience.
Real-World Examples: Applying the CAP Theorem
To better understand the practical impact of the CAP Theorem, let’s look at a few examples from real-world systems:
Financial Systems: CP (Consistency + Partition Tolerance) is crucial here. Financial transactions, like payments or bank transfers, must be consistent across the system to prevent anomalies or fraud. Systems like HBase are often used in scenarios where consistency is more important than being available during network partitions.
E-commerce Platforms: In these systems, availability is often the priority. Even during high-traffic periods (like Black Friday), ensuring that users can browse, place orders, and make payments without experiencing downtime is critical. Systems like Cassandra (an AP model) are well-suited for this kind of operation.
Social Media Apps: In platforms like Facebook or Twitter, where users expect constant uptime, the system prioritizes availability and partition tolerance. Temporary data inconsistencies might be acceptable, as long as users don’t experience downtime or unresponsiveness.
Navigating the Trade-offs with the CAP Theorem
The CAP Theorem is not just a theoretical concept—it's a real-world guide that helps engineers and architects design systems with the right balance of consistency, availability, and partition tolerance based on the unique needs of their applications.
In distributed systems design, understanding the trade-offs outlined by the CAP Theorem will help you make informed choices about which properties to prioritize. Whether you’re building a small-scale app or a massive global infrastructure, these choices will shape the performance, reliability, and scalability of your system.
By leveraging the CAP Theorem, you can create resilient systems that meet the needs of your users while navigating the complexities of distributed architectures. So, while you may never achieve all three properties simultaneously, you’ll always have a clear path to make smart trade-offs based on the priorities of your application and the challenges of your specific use case.
Conclusion: Building Scalable and Resilient Systems with Thoughtful Design
In this guide, we've explored a wide array of critical system design principles, each contributing to the creation of scalable, efficient, and high-performing architectures. We started by examining caching strategies, showcasing how tools like Redis and Memcached can significantly reduce latency and enhance application responsiveness by efficiently managing frequently accessed data.
From there, we delved into the fundamentals of Redis and Memcached, highlighting their unique strengths and use cases. Redis, with its advanced data structures and persistence capabilities, shines in scenarios demanding real-time processing, while Memcached's simplicity and speed make it ideal for lighter caching tasks.
In the next part, we'll dive into the concept of back-of-the-envelope estimations, a practical technique for quickly assessing system requirements related to load, storage, compute, and bandwidth. This approach equips architects with the ability to swiftly evaluate the feasibility of a system and make informed decisions early in the design process, ensuring that the architecture aligns with the desired scale and performance expectations.
The CAP Theorem provided a framework to understand the trade-offs between consistency, availability, and partition tolerance. By unpacking these concepts, we emphasized the importance of aligning system requirements with business priorities.
Finally, we tackled database scaling strategies, from indexing and partitioning to more advanced configurations like master-slave and multi-master setups. These techniques ensure that databases can grow alongside the demands of modern applications while maintaining reliability and performance.
These interconnected principles form the backbone of scalable and adaptable system design. Whether it's optimizing cache usage, balancing trade-offs in distributed systems, or scaling databases for massive workloads, every decision shapes the system's ability to evolve with future demands.
Looking ahead, we’ll dive into advanced real-world implementations and case studies, equipping you with actionable insights to navigate complex system design challenges. Stay tuned for more practical strategies and deeper explorations to help you build systems that truly stand the test of time!
Finished reading it in between my sub classes. Definitely recommend it to anyone trying to understand system design 😄