
How Systems Really Fail, Part IV
The complexity problem: why no one designed the system, why no one fully understands it, and why it works anyway.



The System Has No Architect
The first essay argued that distributed systems fail in the spaces between their components. The second argued that the system you observe is a delayed, partial projection of a system that has already moved on.
The third argued that the control loops you close on that projection cannot stabilise the system you have.
Each was a structural failure (composition, observation, control) and each was localisable: you could point to where the failure lived. This essay is about the failure that is not localised anywhere.
The first three essays assumed there is a system to fail. Call it S, the object engineers compose, observe, and control. The composition fails because interfaces hide state. The observation fails because dashboards project S into a representable space and discard the rest. The control fails because the loop cannot reach the parts of S that matter.
In all three cases the failures are gaps between S and the operator’s representation of it. The argument of this essay is that, past a certain scale, S is not the object the operators think it is.
Production distributed systems at scale are complex systems in the technical sense the term carries in the work of Perrow, Cilliers, Snowden, Leveson, and Dekker. Their behaviour is not the sum of their parts.
Their failure modes are emergent, properties of the whole that no component possesses in isolation. They have no architect. They cannot be modelled in their entirety by any individual.
And they sit, by construction, near the edge of failure, because the same competitive pressure that makes them efficient drives them toward the boundary of safe operation.
The three earlier failures are manifestations of this. The gaps between components cannot be closed because nobody knows where the gaps are. The dashboards cannot be made complete because the system is dimensionally larger than any representation.
The control loops do not close because the plant is not a plant in the textbook sense; it is an emergent process whose dynamics are not contained in any single component’s specification.
Past a certain scale, the system is not the object the operators think it is. And complex systems do not yield to the methods that produced reliable software at small scale.
Four incidents, mechanically reconstructed.
The 2003 Northeast Blackout, where a race condition in one utility’s alarm system propagated, through coupling no one had mapped, into a cascade that affected fifty-five million people.
The AWS S3 outage of February 2017, where one mistyped command exposed a dependency graph no individual had seen end to end.
The Cloudflare WAF outage of July 2019, where one regular expression, deployed globally in seconds, took down a large fraction of the internet’s HTTPS.
And, because the thesis is that these failures are structural rather than historical, a fourth: the Cloudflare outage of November 2025, where the same company repeated a structurally identical failure six years later for reasons unrelated to the specific bug.
Four emergent modes: cascade through coupling, concentration through scale, worst case from interaction, and the recurrence that proves the pattern is not an accident.
What kind of object is a production system?
The canonical work is Charles Perrow’s Normal Accidents (1984), written after Three Mile Island to characterise the systems in which accidents become statistically inevitable.
His framework has two axes. Interactive complexity is how many ways the components can affect each other, including ways the designers did not anticipate.
Coupling is how tightly they are connected in time, whether a failure must propagate immediately or whether there is slack to absorb it.
Loosely-coupled, linear systems (assembly lines, road networks) fail in expected, containable ways.
Complex, tightly-coupled systems (nuclear plants, refineries, the financial system, the internet) fail in ways their operators did not anticipate, and the failures propagate before anyone can intervene.
Perrow’s claim is sharp: complex tightly-coupled systems are not made safe by adding safety features. Past a threshold, features add interactions, which add failure modes. The system has accidents as a normal property of operation, not a deviation from it.
As he restated it in 2012, a normal accident is one where everyone tries hard to play safe, but unexpected interaction of two or more failures (interactive complexity) causes a cascade (tight coupling).
Production distributed systems lie at the far end of both axes. The interactive complexity is enormous: every service has dozens of dependencies, each version-skewed against the others, interacting through coupling paths invisible in the architecture diagrams.
The coupling is tight: cache TTLs in seconds, retry budgets in tens of milliseconds, timeouts tuned down over years until they barely accommodate the steady state. There is no buffer left.

Figure 1, Perrow’s two-axis taxonomy. Systems in the upper-right quadrant produce accidents as a normal property of operation. Latency optimisation and dependency growth push production distributed systems monotonically toward the extreme corner.
Three frameworks sharpen the point. Cilliers distinguished the complicated (many parts, knowable structure, holdable in one head) from the complex (interactions producing behaviours not present in any part and not predictable from the specifications).
Snowden’s Cynefin adds the prescription: in complex contexts cause and effect are clear only in retrospect, so operators must probe, sense, and respond rather than analyse and execute.
Leveson’s STAMP reframes accidents as failures of control over the interactions between components, not failures of the components themselves.
The compressed claim: the methods that produce reliable software at small scale cannot transfer to large scale, because the object they were built to control is no longer the object that exists.
Cascade: the Northeast Blackout, 14 August 2003
At 12:15 EDT, the state estimator at MISO, the reliability coordinator for much of the Midwest and Ontario, began diverging from its measurements.
A state estimator infers load and voltage on every line from noisier telemetry every few minutes; when it converges the operator has a coherent picture of the grid, and when it does not the operator is blind to anything not directly measured.
An analyst traced the divergence to a tripped Indiana line, fixed the topology by hand, then forgot to re-enable the estimator’s automatic trigger.
From 12:37 until 16:04, the window in which the cascade silently assembled itself, MISO’s contingency analysis was effectively offline: operators could no longer answer “what happens if line X trips?” because they had no current model of where the lines were.
At 13:31 EDT, FirstEnergy’s Eastlake Unit 5 tripped while carrying 612 MW and 400 MVAr of reactive power. The lost generation should have been absorbed; the lost reactive support depressed voltage across northern Ohio.
At 14:14 EDT, the alarm processor of GE’s XA/21 system at FirstEnergy’s Akron control centre deadlocked. The control room was entirely alarm-driven: operators responded to alarms rather than watching the mimic.
A latent race condition, a deadlock under high event-queue depth, silently stopped the primary alarm server. No error was raised. The backup took over, inherited the same growing queue, and deadlocked too.
From then until well after the cascade ended, operators believed they were watching a current, stable grid. They were watching a stale snapshot from before the cascade started, with no signal it was stale.
For three and a half hours the operators were looking at a stale snapshot with no signal that it was stale. The dashboard was not wrong. It was describing a system that no longer existed.
At 15:05, 15:32, and 15:41 EDT, three northeast Ohio lines sagged into trees and tripped. Each loss pushed its load onto the survivors, which carried more current, heated, expanded, sagged, and contacted more vegetation.
The cascade is a positive-feedback loop in continuous time: the same physics that produces normal operation produces accelerating failure once a threshold is crossed.
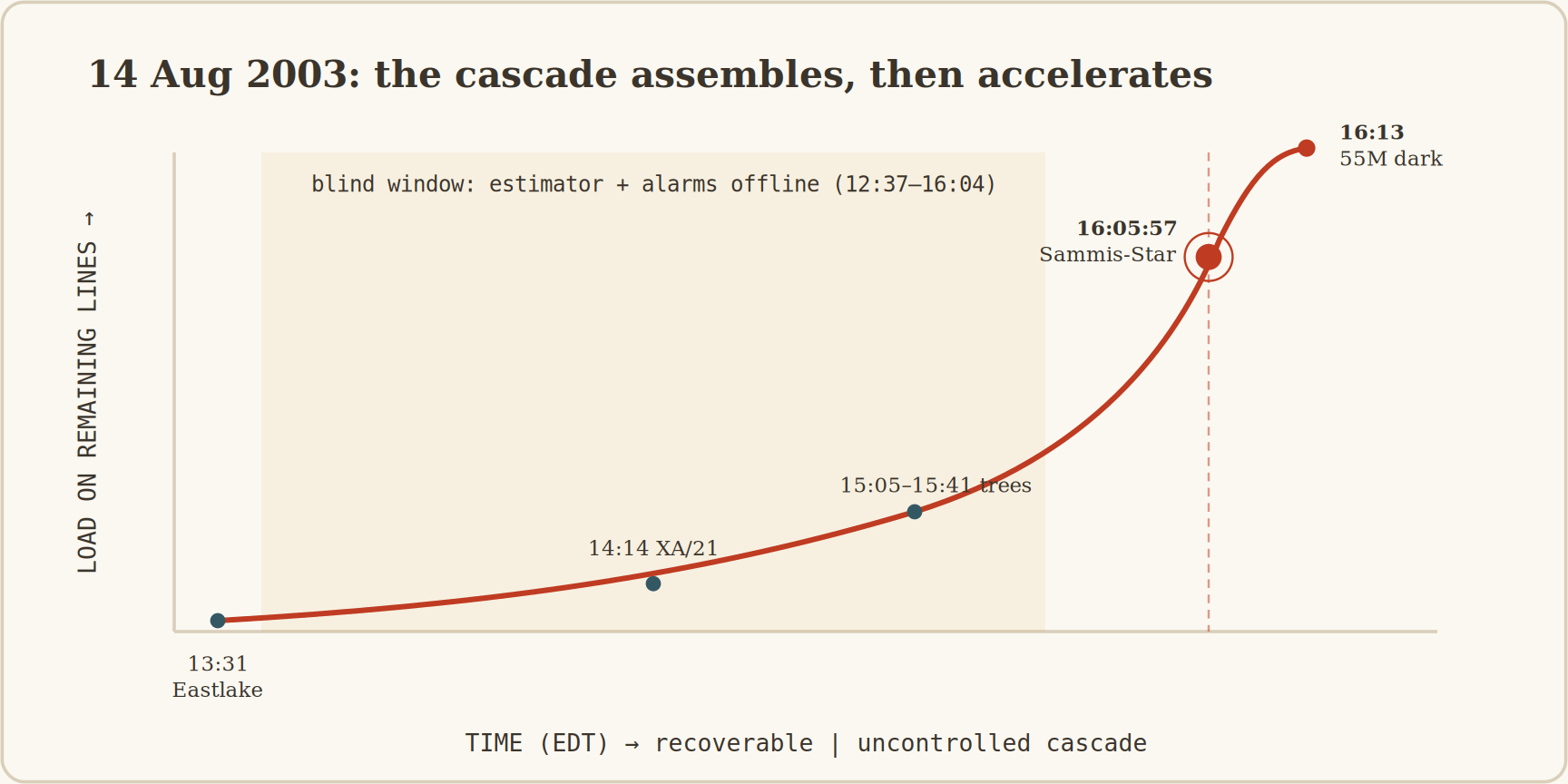
Figure 2. The cascade assembles slowly inside a 3.5-hour blind window, then accelerates. The transition is sharp: before 16:05:57 the event was confined to Ohio and recoverable by load-shedding; after it, the cascade propagated at the speed of protective-relay action.
At 16:05:57 EDT the Sammis-Star line tripped, not from a tree but from over-current. That was the transition point. After it the cascade became uncontrolled, propagating across the interconnection in milliseconds to seconds per trip.
Within eight minutes, lines tripped across Ohio, Michigan, Pennsylvania, New York, and Ontario; the Eastern Interconnection separated into islands; generators tripped as frequencies diverged from 60 Hz. By 16:13, roughly 508 units at 265 plants were offline and fifty-five million people had lost power.
The US-Canada Task Force estimated four to ten billion dollars in losses and named four causes: two operational (unmaintained vegetation, failure to shed load in time) and two observational (no effective contingency analysis, failure of the monitoring tools).
The interesting feature is not the bug. The continental cascade was contingent on the interaction of three unrelated things: trees in Ohio, an alarm system that worked correctly except under one event-ordering pattern, and a grid coupled tightly enough that a loss in Ohio reached Ontario in eleven minutes.
None was dangerous in isolation; the danger was emergent from the combination. No component was outside its specified parameters when the cascade began.
In Leveson’s terms, the regional control structure had not been designed to enforce the constraint that no single utility’s blindness shall propagate beyond its control area, and the cascade would have happened the same way had the XA/21 bug been a different bug producing the same blindness in the same window.
AWS S3, 28 February 2017
At 9:37 AM PST, an authorised S3 engineer ran a routine playbook to remove a few servers from the billing subsystem. One parameter was wrong, and the command removed a much larger set.
A familiar story so far: a fat-finger event, an under-validated tool, a blast radius beyond intent. The interesting part is what happened next.
The removed servers also supported the index subsystem (metadata and location for every object, required for GET, LIST, PUT, DELETE) and the placement subsystem (which depends on the index).
Both dropped below the capacity they needed and entered a state requiring a full restart.
Here the structural problem surfaced. AWS later wrote that the full restart, relied on since launch, had not been run on the index or placement subsystems in their larger regions for many years. S3 in us-east-1 launched in 2006, and the metadata had since grown by orders of magnitude.
The restart procedure, designed at a far smaller scale, took dramatically longer than expected, because each system coming back had to validate a metadata store far larger than the procedure assumed, and the validation scaled non-linearly. Roughly four hours of impact.
What failed during those four hours is the substantive part.
S3 had quietly become a hidden dependency for a remarkable fraction of the public internet: Slack, Quora, Trello, Imgur, Medium, Coursera, GitHub release artefacts, Docker Hub, Adobe Creative Cloud, parts of Zillow and Expedia, each having independently chosen S3, each apparently unaware how many others had.
The cumulative effect was a single point of failure for a non-trivial percentage of the public internet that no organisation had ever ratified.
The cutting detail: AWS’s own Service Health Dashboard depended on S3 to host its status icons, so it could not visually update to reflect the outage of the service it depended on. The icons stayed green because the red ones could not load.

Figure 3. The concentration paradox. Each spoke is an independent, individually-rational decision to use the cheapest reliable object store. Nobody ratified the convergence and nobody can see it. The self-loop is the recovery-dependency cycle: the status page for S3 was itself served from S3.
The shape here is not cascade. The failure was localised to one region of one service. What made it catastrophic was concentration: an enormous number of independent systems had converged on the same choice without anyone designing the convergence.
None had chosen to share fate; they had each chosen, separately, the cheapest reliable object store, and that was S3 in us-east-1. The shared fate was emergent from the aggregation of independent decisions.
Network science calls the mechanism preferential attachment: independent decisions under similar constraints converge on a few providers, and the providers become single points of failure for the aggregate without anyone designing it.
The most reliable service in a category becomes the largest single point of failure for that category, precisely because it is the most reliable. The convergence is rational at the individual level and catastrophic at the aggregate level, and no one can intervene against it because no one can see how many others made the same choice.
This is emergence of a different kind from cascade. The blackout’s was dynamic, failures propagating along time-coupled paths in minutes.
S3’s was structural, dependencies accreting along static paths nobody maintained a record of, over a decade. Both are failures of the whole, in the precise sense that no subsystem was responsible.
What made the blast radius continental was the way thousands of independent decisions had made S3 a chokepoint no individual fully understood.
AWS’s fix, beyond safer commands, was to partition the index subsystem into cells so a future restart brings back one cell at a time.
In Perrow’s terms, that is an explicit attempt to reduce coupling and reintroduce slack between subsystems whose tight coupling had silently emerged from organic growth.
Worst case from interaction: Cloudflare WAF, 2 July 2019
At 13:42 UTC, a Cloudflare engineer deployed a minor change to the WAF Managed Rules, a new rule meant to improve detection of inline JavaScript used in cross-site-scripting attacks.
It went out via Quicksilver, which propagates configuration to every edge server globally in seconds, by design, so emergency security responses do not wait for a gradual rollout.
Three minutes later the first page fired. CPU on every Cloudflare edge worldwide had spiked to 100%. Cloudflare’s network, by 2019 fronting roughly ten percent of the world’s HTTPS, could not process new requests.
Customer sites returned 502s; Cloudflare’s own dashboard, API, and internal tools, all routed through the same edge, went unreachable. At its worst, traffic dropped 82%.
The rule’s structural problem was a trailing pattern of the shape .*(?:.*=.*). A backtracking regex engine handles .* greedily: it matches as much as possible, then, if the rest fails, gives back one character at a time and retries.
With several unanchored .* constructs in sequence, the number of match positions grows combinatorially in the input length. Against an input that almost matches but diverges late, a pattern of the form .*.*=.* with no equals sign explores on the order of n-choose-2 partition points:
quadratic, O(n²), for this shape, and exponential, O(2ⁿ), in pathological cases like (a+)+. Quadratic and cubic blow-ups are equally lethal at millions of requests per second.
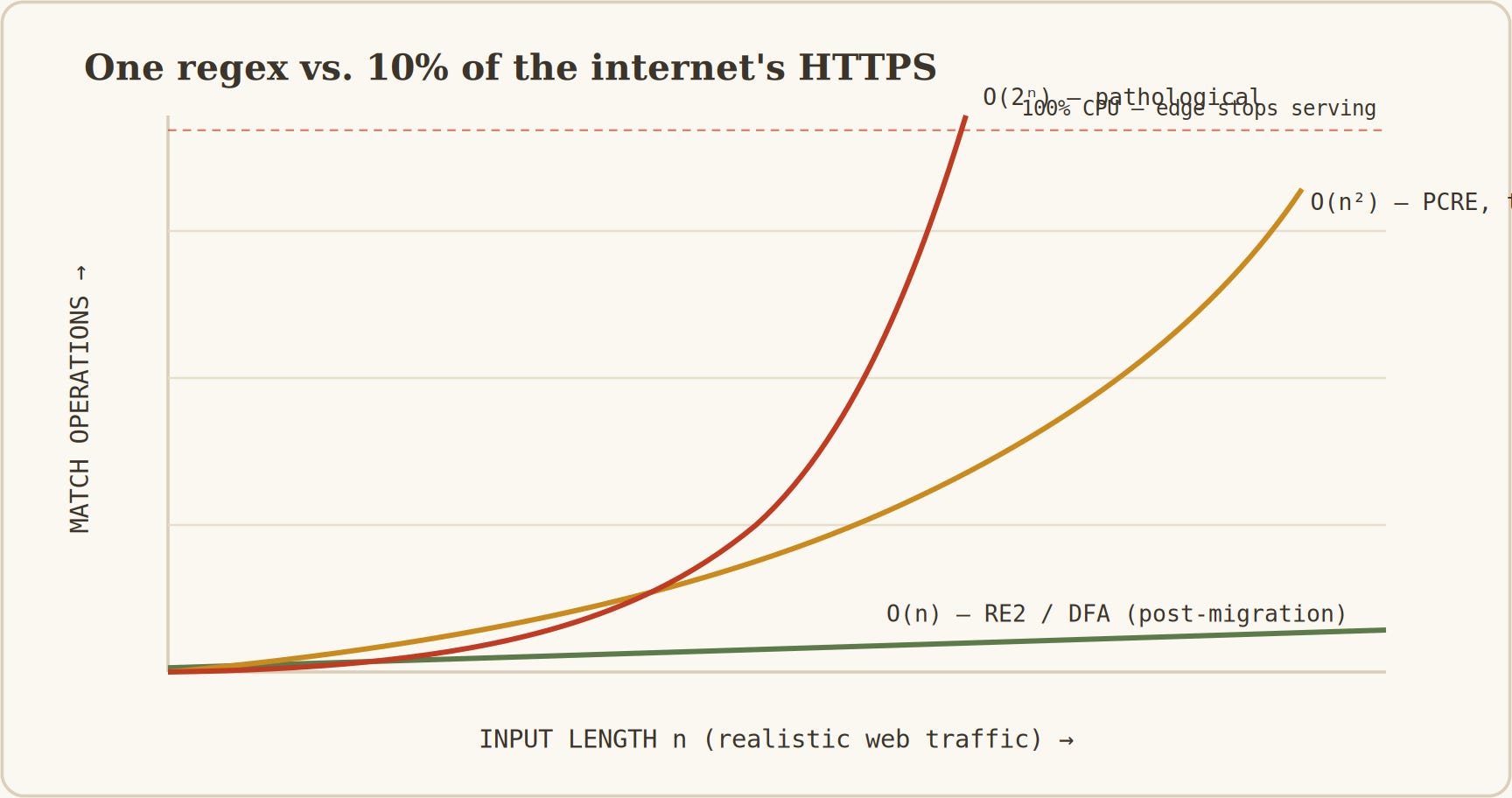
Figure 4. Why one regex took down ten percent of the internet’s HTTPS. PCRE’s backtracking engine offers no complexity guarantee, so on inputs the test author never wrote, the same rule that was fast in the suite explored a quadratic-to-exponential number of paths. RE2’s DFA does one state transition per character: linear, regardless of pattern shape.
This pathology, catastrophic backtracking, is a known property of backtracking engines (PCRE, Perl, Python’s re, JavaScript’s RegExp) on inputs they were not tested against.
Cloudflare’s Lua WAF used PCRE because PCRE ships with Lua, and PCRE has no complexity guarantee: it attempts every backtrack until it matches or exhausts the search.
The rule had passed the test suite. It had even been deployed in “simulate” mode, where the rule runs against real traffic but blocks nothing, explicitly to catch this, but simulate mode still executes the regex on each request and the CPU cost was identical.
Two factors made it worse: the WAF Managed Rules pipeline bypassed Cloudflare’s normal staged rollout (a deliberate speed-against-safety trade for emergency patches), and a CPU-time safeguard that would have caught a runaway regex had been removed by mistake during an earlier refactoring whose explicit goal was to reduce CPU consumption.
The recovery was constrained by the same property that caused the failure: the engineers who needed the kill switch could not reach the control panel, because it runs behind Cloudflare’s own Access product, which routes through the edge.
They used a rarely-exercised bypass, diagnosed it by 14:02, and killed the rulesets at 14:09. Total impact: about twenty-seven minutes, during which Discord, Feedly, Coinbase, and a large share of global HTTPS returned 502s, an aggregate impact orders of magnitude larger than the duration suggests, because Cloudflare had, like S3, become public infrastructure.
The form is worst case from interaction. The system has performance regimes not exercised by any input used in development or testing, exposed only by realistic input at scale.
The regex did not fail under any tested input; the engine did not fail in any benchmark; the pipeline functioned as designed. The fault was emergent from the joint behaviour of a regex, an engine, an input distribution, and a deployment process, each correct in isolation.
This is what Hollnagel calls the underspecification problem: a component’s spec covers anticipated inputs, the system at scale sees inputs no one anticipated, and the behaviour under those is emergent from the implementation, not contained in the spec.
Cloudflare’s fix, beyond restoring the safeguard and staging rollouts, was to migrate from PCRE’s backtracking to an engine based on a deterministic finite automaton, which guarantees linear time regardless of pattern shape because every input character causes exactly one state transition.
That is the move Perrow recommended in 1984: where possible, reduce the interactive complexity rather than defend against its consequences.
Recurrence: Cloudflare again, 18 November 2025
If the three preceding incidents were merely history, a sceptic could argue the field has since learned its lessons.
The strongest evidence against that reading is that the same company, having written one of the most-cited post-mortems in the industry about its 2019 outage, produced a structurally identical failure six years later, for reasons again unrelated to the specific bug.
On 18 November 2025 at 11:05 UTC, Cloudflare deployed a correct permissions change to a ClickHouse cluster, granting users explicit access to metadata for shard tables in a schema called r0.
The problem was a buried assumption elsewhere. A query feeding the Bot Management system listed a table’s columns and had always, by assumption, returned only the default database’s columns.
After the change, it also returned the r0 schema’s columns, roughly doubling the rows. That output fed directly into a “feature file,” the configuration the Bot Management model consumes to score every request as bot or human.
The feature file, normally stable around sixty features, more than doubled to over two hundred. It is regenerated every few minutes and propagated globally, by design, so the system can react to new bot behaviour.
The core proxy preallocates memory for these features and enforces a hard limit of two hundred. When the bloated file hit production it exceeded the limit, and the Rust code did not handle the error gracefully.
It panicked: thread fl2_worker_thread panicked, called unwrap on an Err value. Every request through the Bot Management path returned a 5xx.
The blast radius again included Cloudflare’s own products and downstream a large slice of the consumer internet: ChatGPT, X, Spotify, Canva, Discord. Matthew Prince called it the worst outage since 2019.
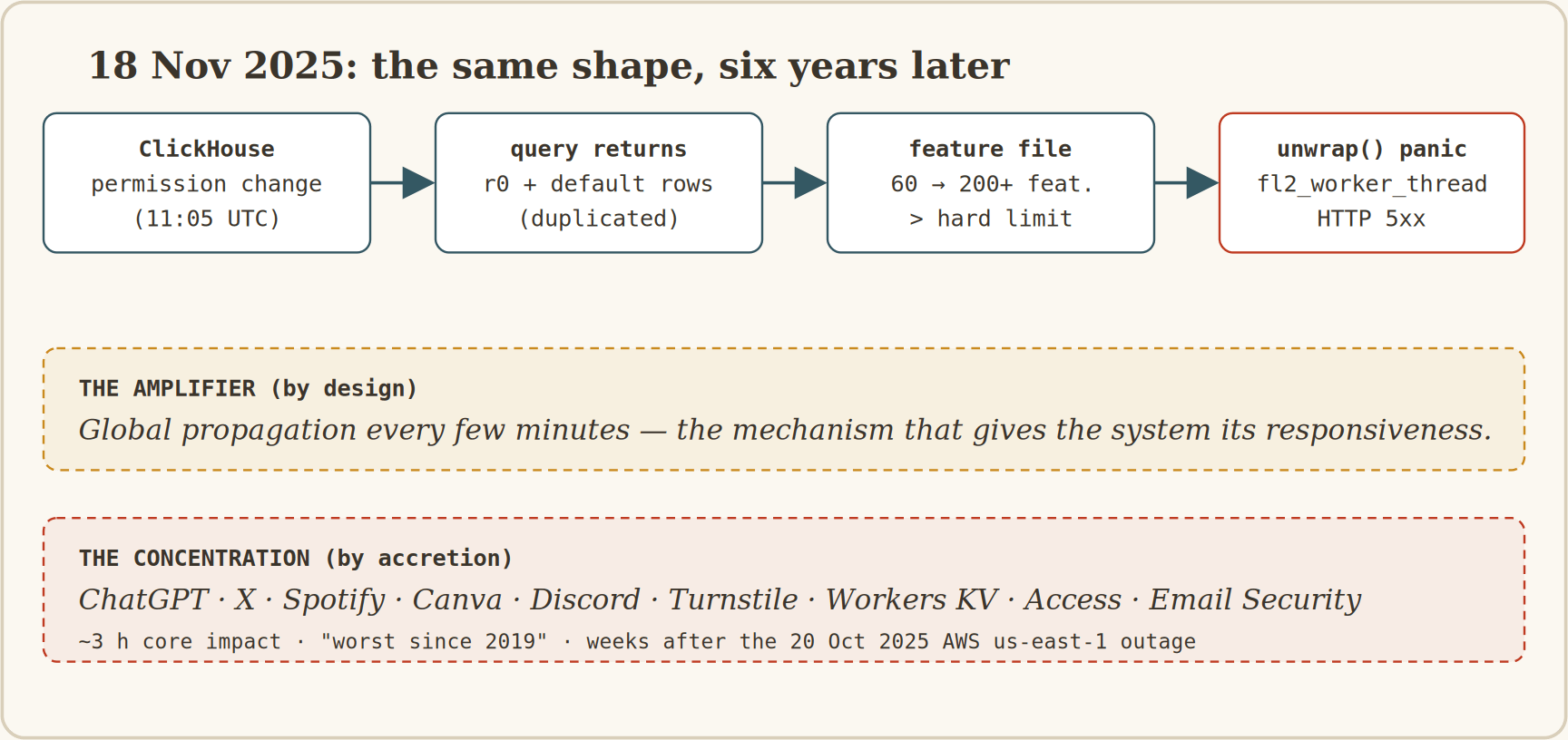
Figure 5, Six years apart, the same shape. A correct local change meets a buried assumption (worst case from interaction); a fast-global-propagation pipeline turns one bad artefact into a worldwide event in minutes (the amplifier); and concentration makes the blast radius the consumer internet.
Read against the three earlier incidents, the recurrence is almost eerie. It is worst case from interaction, in the 2019 sense: a query that behaved one way for years behaved differently under a correct change, on an input nobody had specified.
It is concentration, in the 2017 sense, and it landed only weeks after a major AWS us-east-1 outage on 20 October 2025. And the amplifier is the same amplifier as 2019: the fast global propagation path, the very mechanism that gives the system its responsiveness, is what turned one bad artefact into a worldwide event in minutes.
The deepest point is the one a casual reader misses. Cloudflare did learn the 2019 lesson; they migrated regex engines, added staged rollout, restored safeguards.
None of it prevented 2025, because the 2019 lesson was about regular expressions and the 2025 failure was about a database permission, a buried assumption, a hard-coded limit, and an unwrap that should have been a fallback. The two share no component. They share a structure.
The 2019 fix did not prevent 2025, because the two incidents share no component. They share a structure. You cannot patch a structure by patching the part that happened to express it last time.
The emergent forms, named
The incidents are distinct shapes of emergence. Cascade (2003): tight coupling, a fault propagating faster than operators can intervene; the reach is a property of the topology, not of any line or processor.
Concentration (2017, and again 2025): a structural property nobody designed, accumulated through years of independent decisions; the blast radius of a foundational service’s failure is a property of how many systems converged on it, and it grows silently because no organisation can see across all the adoptions.
Worst case from interaction (2019): regimes not exercised by the inputs the system was tested against, exposed by the inputs it actually sees; the failure is in no component’s specification because no specification covers all realistic inputs.
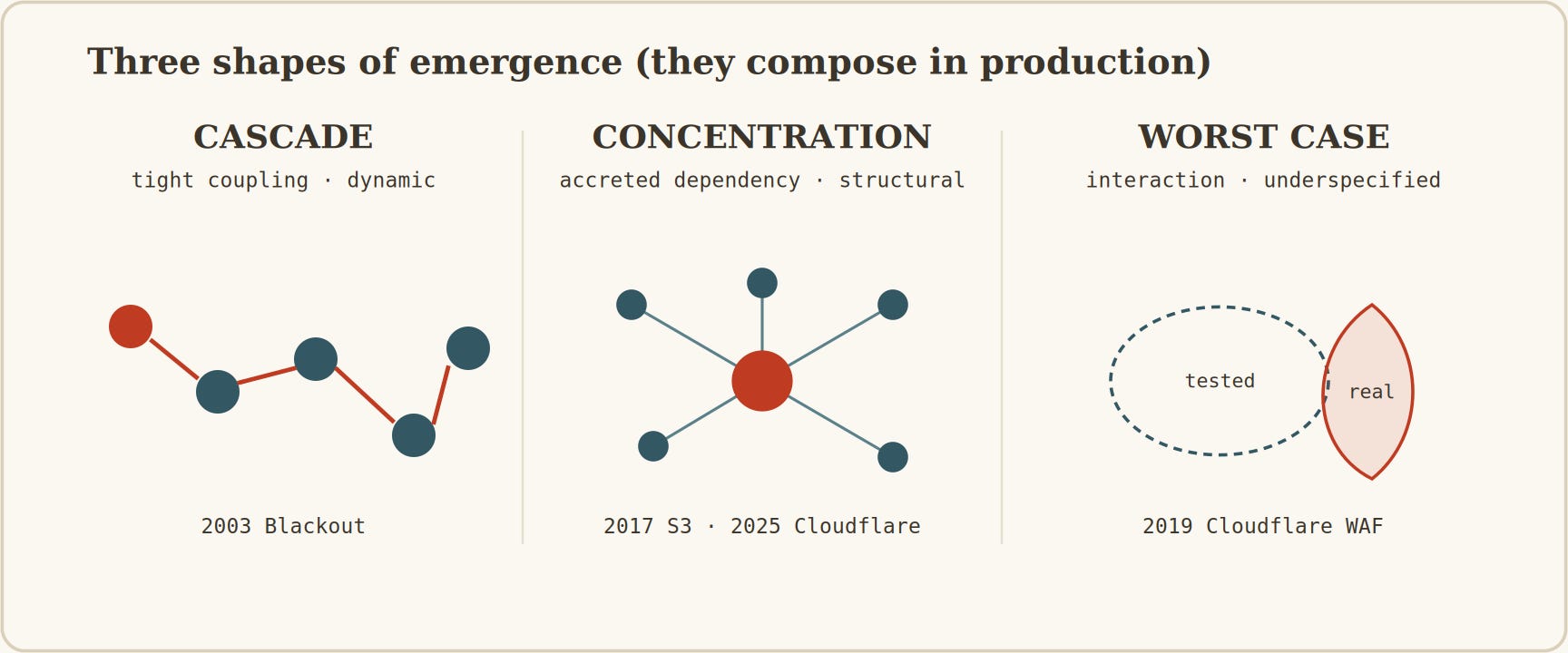
Figure 6 — Three shapes of emergence. In production they compose: concentration creates the conditions for cascade; a worst-case interaction triggers a cascade through tightly-coupled subsystems. November 2025 was all three at once.
The three compose in production. Concentration creates the conditions for cascade: when many systems share fate, a fault in the shared component propagates instantly.
Worst-case interactions trigger cascades through tightly-coupled subsystems: the regex spike that takes down the edge takes down the dashboard the operators need to push the kill switch.
The deeper claim is that the three failures of Parts I, II, and III are themselves emergent properties of the same kind of system:
composition gaps appear at interfaces nobody designed end to end;
observation failures appear because the system’s behaviour is dimensionally larger than any representation, with the dimensions that matter most during novel failures being exactly the ones the projection discarded;
control failures appear because the loops close on a plant whose dynamics are not contained in any single component.
the projection model
It is worth making the claim precise, because precision turns a metaphor into a tool.
Let S be the system as it actually is: the full state, every dependency, every cached value, every in-flight retry, every input it will ever see. S lives in an enormous, high-dimensional space, and no human or dashboard holds it.
What everyone works with is a representation R, obtained by a projection (call it pi) that maps the system into something small enough to fit in a diagram, a metrics store, or one engineer’s head.
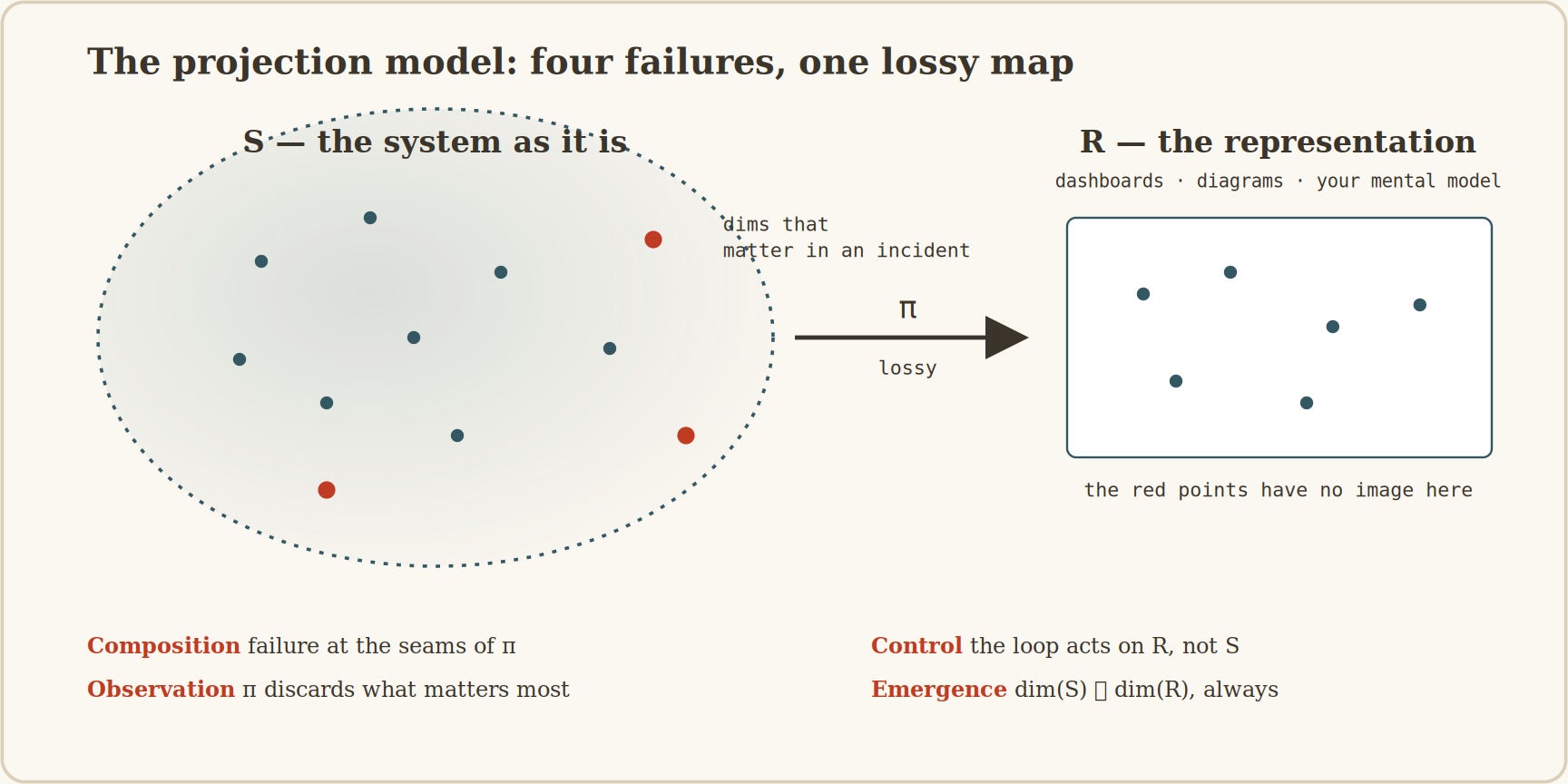
Figure 7, The unifying picture. Every artefact an operator touches is a point in R. The system lives in S. In the steady state the two agree, because the system spends most of its time in a regime pi captures. An incident is precisely the event of S moving into the part of itself that pi threw away.
The four failures are four ways pi betrays you. Composition is a failure at the seams of pi: each subsystem is built against its own local projection of its neighbours, and where two such projections meet, the assumptions need not agree (the 2025 query is a perfect specimen).
Observation is the claim that pi loses, preferentially, the dimensions that carry the most signal during a novel failure, because a dashboard is built from the dimensions that mattered in past incidents and a novel incident is by definition one whose decisive dimension was not salient before.
Control is the observation that the loop closes on R, not S: it can be perfectly stable on R and diverging on S, and the operator sees stability until the divergence reaches a dimension pi still tracks.
Emergence is the statement that the dimension of S vastly exceeds that of any R a human or tool can hold, and that no enrichment of R closes the gap, because every dimension you add to the dashboard expands the interaction surface of the system you are charting.
That is the formal residue of Perrow: adding observation is adding components, adding components is adding interactions, and the system you can fully observe is, for that reason, not the system you have.
The system has no architect
What follows, and what engineers trained on smaller systems underestimate, is that production distributed systems at scale have no architect. This is not about staffing. It is structural.
The system is the accumulated artefact of thousands of independent decisions by hundreds of engineers over years, most of whom have left, none charged with maintaining a coherent end-to-end model.
The architecture diagrams capture, at best, the model of one engineer, on one day, of the slice they were looking at. The whole system is not in any document because it is not in any individual’s head.
This is the Conway’s Law observation, after Mel Conway’s 1968 paper that organisations design systems mirroring their communication structure. The deeper version is Daniel Dennett’s phrase: competence without comprehension.
The system serves traffic, accepts payments, delivers content, without any individual comprehending the full mechanism. The competence is real; the comprehension exists nowhere. There is a parallel from political economy.
Hayek’s 1945 paper argued against central planning on epistemic grounds: the knowledge to coordinate a complex economy does not exist in any single mind, but is distributed across millions of agents holding local, tacit knowledge that cannot be efficiently aggregated.
The argument transfers directly. Conway, Dennett, and Hayek point at the same fact from three lineages, which suggests it is real and not an artefact of one discipline.
This is hard for engineers to accept in proportion to how good they are. The instinct that produced their career, that one can read the code and understand the system, works up to about the size of a single service team.
Past that it stops, and the engineer who insists on retaining the model loses the ability to operate the system. The mature posture is not to know the system but to navigate it: Charity Majors describes moving from understanding systems to interrogating them; the resilience-engineering school calls it coping with complexity, the operator inside the system rather than above it.
In a complicated system you learn the system and then operate it. In a complex system you operate the system and learn what you can, knowing some of what you learn will be obsolete by the time you have learned it.
The competent on-call engineer at scale is therefore not the one who knows the most, but the one with the best discipline for forming hypotheses, sizing interventions, observing responses, and updating beliefs.
That discipline is what decides whether an incident lasts twenty minutes or twenty hours.
Drift into failure
There is a phenomenon, named by Sidney Dekker in Drift into Failure (2011) and rooted in Jens Rasmussen’s 1997 paper, that explains how complex systems reach the boundary of safe operation without any single decision being responsible.
A system operates in a state space bounded by three pressures, each a gradient. Economic pressure pushes toward higher throughput at lower cost. Workload pressure pushes toward simpler procedures and less manual intervention.
The third is the boundary of functionally acceptable performance, the safety boundary, beyond which catastrophic failure is statistically expected.
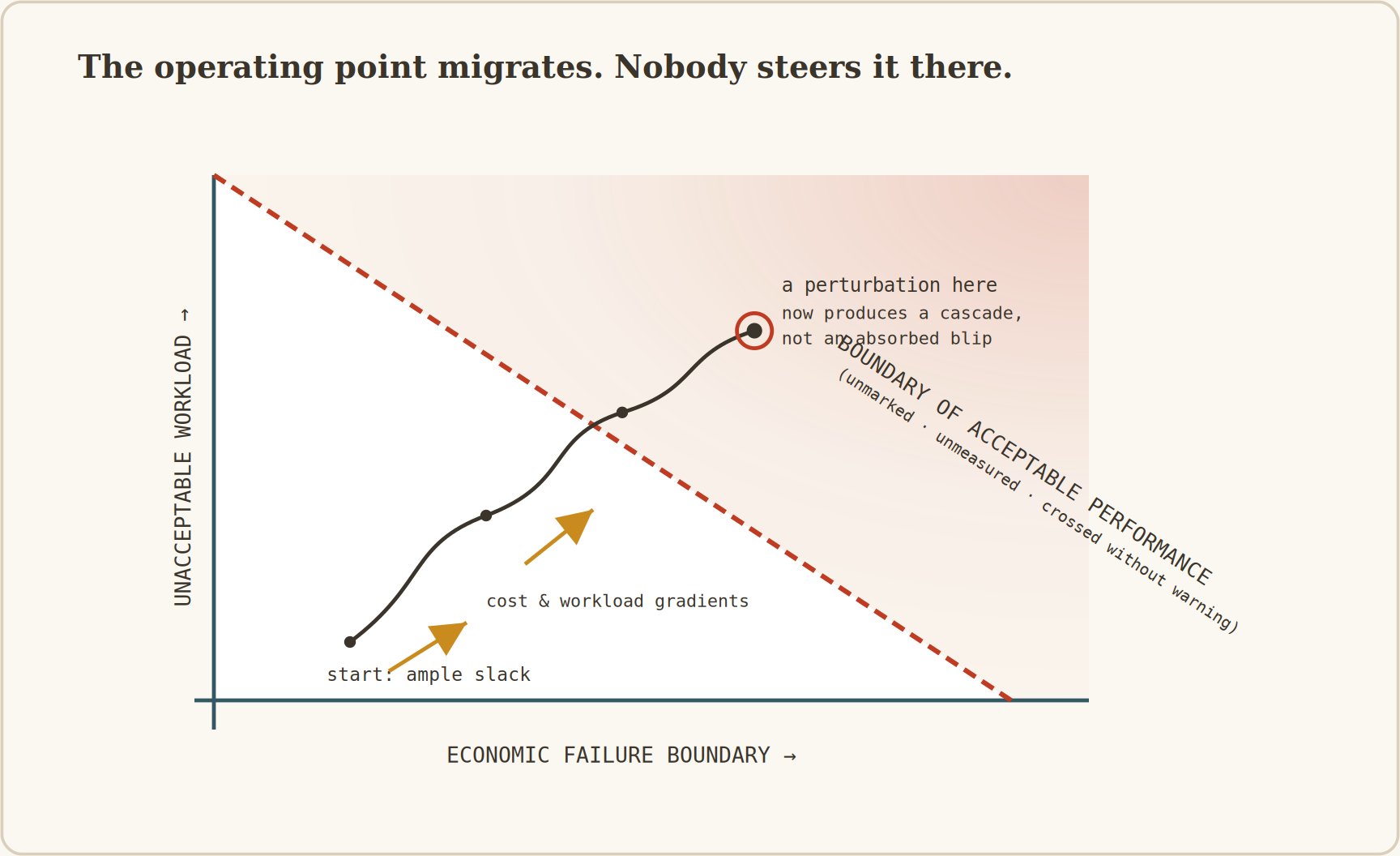
Figure 8: Rasmussen’s state space. Two boundaries (economic, workload) are quantified, visible, and rewarded. The third, safety, is unmarked and gives no warning at the crossing, because the crossing is statistical, not deterministic. Each locally-rational optimisation removes slack and nudges the operating point along the cost gradient.
The three pressures are not balanced. Economic and workload pressure act continuously and visibly: quantified in dashboards, named in reviews, the subject of every planning cycle. The safety boundary is invisible.
The system gives no warning at the crossing, because the crossing is statistical: a system past the boundary does not fail immediately, it fails with elevated probability per unit time, empirically indistinguishable from operating safely until it fails.
The result is a steady migration toward the safety boundary, driven by the visible pressures, the boundary unobserved until it is crossed.
Applied to production systems: every optimisation that reduces latency or cost is a step toward the boundary. Every timeout tightened for P99, every retry budget cut, every cache TTL shortened, every connection pool sized closer to peak.
Each is locally rational, and the cumulative effect is to remove slack. Slack absorbs perturbations; a system with no slack is tightly coupled, the condition under which interactive complexity becomes accidents. The drift is not a decision to operate unsafely.
It is many decisions to operate slightly more efficiently, and at no point did anyone authorise the trajectory.
Per Bak’s self-organized criticality (1987) showed that systems under continuous driving organise themselves to a critical point, where a small perturbation can produce an avalanche of any size, with sizes following a power law (the two-dimensional exponent is commonly quoted near 1.2, though it is non-universal and contested; the heavy tail is robust regardless).
Carlson and Doyle’s Highly Optimized Tolerance (1999) is more directly applicable: systems explicitly optimised for robustness against expected disturbances become fragile against unexpected ones, producing power-law failures without any external driving.
They are critical because they were engineered to be, the optimisation having consumed every margin against the perturbations the optimiser did anticipate.
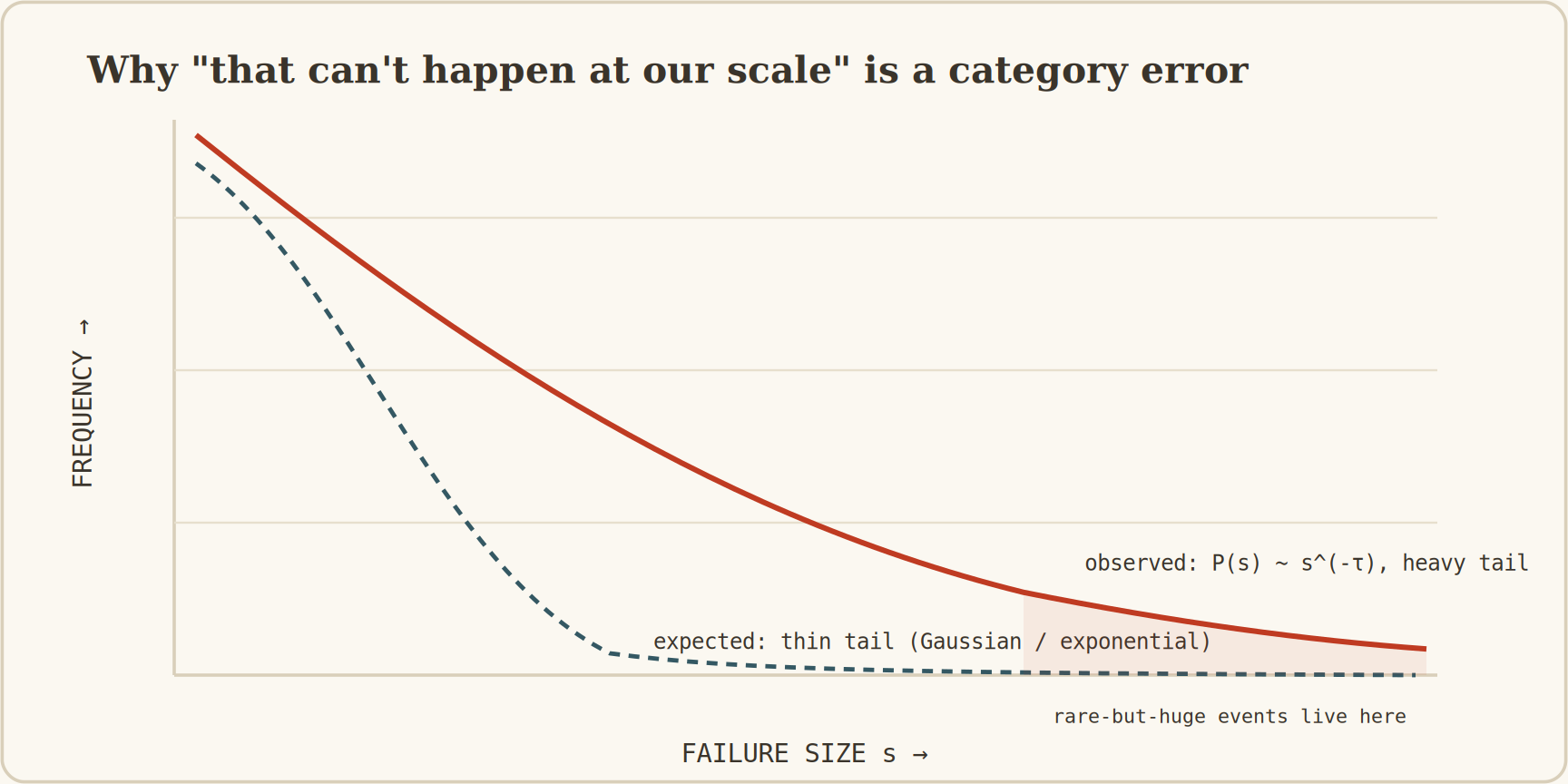
Figure 9. Why “that could never happen at our scale” is a category error. Optimised systems produce power-law failure sizes, not the thin-tailed distribution intuition assumes. The catastrophic outage is not an outlier off the curve. It is a point on the curve, in the tail the optimisation built.
The implication is uncomfortable. The reliability of a mature system is not a function of how careful its operators are.
It is a function of how much slack they have preserved against the cost pressure that would remove it.
A team that fights to keep slack, holding redundant capacity, leaving timeouts loose, refusing to push retry budgets to the minimum, is doing the most important reliability work, and it is the work least visible in the metrics.
This is also why incidents cluster: with margin, small perturbations are absorbed; at the boundary, the same perturbations cascade.
Incident frequency is perturbation frequency times the probability the system is currently at the boundary, and that probability rises with drift, and drift is monotonic without deliberate effort against it.
The system gets less safe over time even as no one decides to make it less safe.
Drift is the boundary approaching. Cascade is what happens when the boundary is crossed. The system gets less safe over time even as no one decides to make it less safe.
What operations looks like under emergence
The practices that work here are the post-Perrow tradition of resilience and site-reliability engineering, tied together by the recognition that no model is reliable and that operations must proceed by probe-and-respond.
Chaos engineering, deliberately injecting failures into production, rests on the premise that behaviour under failure cannot be predicted from the components but only discovered by observation, so the system must be perturbed deliberately, with bounded blast radius and operators present.
Error budgets make Rasmussen’s invisible boundary visible in the same units as the economic pressure on the other side: define a service-level objective, track consumed unavailability as a budget, and slow releases when it is exhausted.
The arithmetic is sobering:
99.9 percent availability allows about 43.8 minutes of downtime per month.
99.95 percent allows about 21.9 minutes; a single cascade exhausts it.
99.99 percent allows about 4.38 minutes; a 27-minute Cloudflare-style event blows two quarters of budget.
99.999 percent allows about 26 seconds per month, essentially no human-in-the-loop budget at all.
The budget is the boundary, denominated in minutes, which is why high-availability targets and aggressive release velocity are in genuine, not rhetorical, tension.
Blameless post-mortems are a technical practice as much as a cultural one: the information value of a post-mortem is proportional to the accuracy of the reporting, and accuracy is proportional to the safety the reporter feels.
Ron Westrum’s typology (pathological, bureaucratic, generative) formalises this: only generative cultures, where bad news is welcomed because it is operationally valuable, produce the post-mortems complex systems need.
Game days and failure injection are variants of one principle: behaviour under stress cannot be modelled, it must be observed, and the observation must be staged before the real failure, because in the real failure operators cannot slow down to learn.
What unites these is the acceptance of irreducibility: the model is incomplete by construction and is updated by observation under controlled perturbation, not by deduction from specification. Operations becomes an empirical discipline, closer to experimental science than to mechanical engineering.
The practitioners who absorb this invest in observability (not because dashboards reveal the truth, but because they are the only handle on a system you cannot model), in chaos engineering (because the alternative is discovering breakages during real incidents), and in slack (because they have read enough post-mortems to know which systems fail catastrophically).
The ones who have not make the opposite choices and look reasonable doing it: eliminate slack to cut cost, reduce observability to cut noise, avoid chaos engineering because it occasionally causes outages.
They discover, eventually, that they have built a system both more efficient and more catastrophic when it fails, in proportion to the savings.
Operators as the homeostatic mechanism
There is a way to name what operators are, structurally, that systems biology names directly.
In an organism, homeostasis maintains internal state against perturbation: temperature, glucose, pressure, pH within a fraction of a unit despite continuous challenge.
The mechanisms are not centralised; they are distributed across hundreds of overlapping negative-feedback loops, none responsible for the overall stability.
No part of the body is in charge of being alive; being alive is what the parts, in aggregate, are doing.
The operator function is the homeostatic mechanism in this precise sense. Operators are the negative-feedback loop that prevents Rasmussen drift from becoming Rasmussen crossing, the slack reintroduced when cost-cutting removes it elsewhere, the compensating force against every gradient that would otherwise push the system over the boundary.
The system is stable not because the engineering is good but because operators continuously absorb the perturbations the engineering does not address.
The on-call engineer reverting a deployment at 03:47 UTC is not interrupting normal operation. They are participating in it. The reverting is what the system is doing, through them, to keep itself alive.
The systems do not work. The operators work, and the systems usually fail only when the operators lose the ability to see, infer, intervene, or comprehend.
This is structural and testable. Remove the operators and the system enters its statistically expected failure regime within hours to days.
With competent operators present, it runs, degraded but functional, for years against perturbations that would individually crash it.
The competence is in the loop, not in the system. Yet organisations reward the visible artefacts (clean architectures, well-factored code, comprehensive tests, capacity plans) and underinvest in the invisible work of compensating, absorbing, and quietly maintaining slack, treating it as a cost centre rather than the production function it is.
The engineering does not produce reliability. Reliability is the output of the engineering acted on by the operators, in a loop the organisation rarely acknowledges.
This also explains why, beyond a threshold, more automation worsens outcomes. Lisanne Bainbridge’s 1983 paper “Ironies of Automation” catalogued it: automating the routine cases removes the operators’ opportunity to maintain situational awareness, the very faculty they need when the automation fails on a case it was not designed for.
The gains accrue early and visibly; the costs accrue late and on the days that matter most.
The discipline that follows is to treat operators as the load-bearing element, not the engineering: build the observability they need to interrogate the system, build the chaos practice they need to keep their model current, and do not automate them out of the loop; automate the routine inside their loop, so they keep the situational awareness they will need when the automation fails.
Closing the series
Four essays. Four structural failures.
Composition: distributed systems fail in the spaces between their components, because no individual designed both sides of the interfaces.
Observation: the system you see is a delayed, partial, aggregated projection, and the moments when projection and system disagree are the moments that matter most.
Control: the loops you close on the projection cannot stabilise the system, because the plant moves faster than the controller can sample, the actuator is in the blast radius, or the feedback path passes through the failure.
Emergence: the system is bigger than any of these admits. It has no architect. It sits at the boundary by construction, because the pressure that makes it efficient drives it there, and its failure modes are properties of the whole that no model in any individual head can predict.
These are not exceptional. They are the structural conditions under which production systems at scale operate.
The systems do not work because they were engineered to work; they work because the operators, from the SRE on call at 03:47 UTC to the architect drawing dependency graphs in a Confluence document nobody updates, are continuously compensating for the gaps the engineering left open.
What this means for the engineer is twofold.
The technical: the practices that increase survivability (slack, observability, chaos engineering, error budgets, blameless post-mortems, out-of-band control, recovery-dependency mapping, drift monitoring) are expensive, and they are what separates systems that fail gracefully from systems that fail catastrophically.
The epistemic: the appropriate posture is structural humility, knowing the system is bigger than the model, the model is incomplete by construction, and any incident might be the one that reveals a regime nobody had characterised.
The pager will go off again. The dashboards will be lying again. The interventions will assume conditions that have ceased to hold. The system will have drifted, since the last incident, slightly closer to the boundary.
The work is the same work, performed by the same kind of people, against systems that none of them designed and none of them fully understand.
The interesting thing is that this works at all. The accidents are kept rare by humans doing a job whose structural conditions make it nearly impossible, and doing it well enough that the rest of the profession can pretend the systems work on their own. They do not. They never have.
The serious engineer’s contribution, past a certain seniority, is to understand this and act accordingly: to design systems that respect what the operators have to do, build the tools that make their job possible, and write the practices down so the next generation does not learn them from incidents.
The job is hard. It is also the most important job in the engineering function. The systems do not work without it. They never will.
One more thing….
I wrote a deep CUDA guide from exactly this perspective: not isolated tricks, but how to reason about the GPU as a coupled dynamical system whose performance regimes and failure modes (occupancy collapse, memory-bandwidth thrashing, warp divergence, pipeline stalls, register spilling, bank conflicts, tensor-core underutilisation) are structurally the same kinds of seam failures the four essays of this series have described.
If the framework resonates, the guide is where it lands in code.
[Read the CUDA Guide on Gumroad → CUDA Mastery]
This is the final essay in the series How Systems Really Fail. The four parts are best read in order, but each can stand alone.